« February 6, 2019 | Main | April 9, 2019 »
Sunday, April 7, 2019
Reading List: Connected: The Emergence of Global Consciousness
- Nelson, Roger D. Connected: The Emergence of Global Consciousness. Princeton: ICRL Press, 2019. ISBN 978-1-936033-35-5.
-
In the first half of the twentieth century
Pierre
Teilhard de Chardin developed the idea that the
process of evolution which had produced complex life
and eventually human intelligence on Earth was continuing
and destined to eventually reach an
Omega Point
in which, just as individual neurons self-organise to
produce the unified consciousness and intelligence of the
human brain, eventually individual human minds would
coalesce (he was thinking mostly of institutions and
technology, not a mystical global mind) into what he
called the
noosphere—a
sphere of unified thought surrounding the globe just like
the atmosphere. Could this be possible? Might the Internet
be the baby picture of the noosphere? And if a global mind
was beginning to emerge, might we be able to detect it with
the tools of science? That is the subject of this book
about the
Global Consciousness Project,
which has now been operating for more than two decades,
collecting an immense data set which has been, from inception,
completely transparent and accessible to anyone inclined to
analyse it in any way they can imagine. Written by the founder
of the project and operator of the network over its entire
history, the book presents the history, technical details,
experimental design, formal results, exploratory investigations
from the data set, and thoughts about what it all might mean.
Over millennia, many esoteric traditions have held that
“all is one”—that all humans and, in some
systems of belief, all living things or all of nature are
connected in some way and can interact in ways other than
physical (ultimately mediated by the electromagnetic force). A
common aspect of these philosophies and religions is that
individual consciousness is independent of the physical being
and may in some way be part of a larger, shared consciousness
which we may be able to access through techniques such as
meditation and prayer. In this view, consciousness may be
thought of as a kind of “field” with the brain
acting as a receiver in the same sense that a radio is a
receiver of structured information transmitted via the
electromagnetic field. Belief in reincarnation, for example, is
often based upon the view that death of the brain (the receiver)
does not destroy the coherent information in the consciousness
field which may later be instantiated in another living brain
which may, under some circumstances, access memories and
information from previous hosts.
Such beliefs have been common over much of human history and in
a wide variety of very diverse cultures around the globe, but in
recent centuries these beliefs have been displaced by the view
of mechanistic, reductionist science, which argues that the
brain is just a kind of (phenomenally complicated) biological
computer and that consciousness can be thought of as an emergent
phenomenon which arises when the brain computer's software
becomes sufficiently complex to be able to examine its own
operation. From this perspective, consciousness is confined
within the brain, cannot affect the outside world or the
consciousness of others except by physical interactions
initiated by motor neurons, and perceives the world only through
sensory neurons. There is no “consciousness field”,
and individual consciousness dies when the brain does.
But while this view is more in tune with the scientific outlook
which spawned the technological revolution that has transformed
the world and continues to accelerate, it has, so far, made
essentially zero progress in understanding consciousness.
Although we have built electronic computers which can perform
mathematical calculations trillions of times faster than the
human brain, and are on track to equal the storage capacity of
that brain some time in the next decade or so, we still don't
have the slightest idea how to program a computer to be
conscious: to be self-aware and act out of a sense of free will
(if free will, however defined, actually exists). So, if we
adopt a properly scientific and sceptical view, we must conclude
that the jury is still out on the question of consciousness. If
we don't understand enough about it to program it into a
computer, then we can't be entirely confident that it
is something we could program into a computer, or that
it is just some kind of software running on our brain-computer.
It looks like humans are, dare I say, programmed to believe in
consciousness as a force not confined to the brain. Many
cultures have developed shamanism, religions, philosophies, and
practices which presume the existence of the following kinds of
what Dean Radin calls Real Magic,
and which I quote from my review of his book with that title.
- Force of will: mental influence on the physical world, traditionally associated with spell-casting and other forms of “mind over matter”.
- Divination: perceiving objects or events distant in time and space, traditionally involving such practices as reading the Tarot or projecting consciousness to other places.
- Theurgy: communicating with non-material consciousness: mediums channelling spirits or communicating with the dead, summoning demons.
 In 1998, Roger D. Nelson, the author of this book,
realised that the rapid development and worldwide
deployment of the Internet made it possible to expand
the FieldREG concept to a global scale. Random event
generators based upon quantum effects (usually
shot
noise from tunnelling across a back-biased Zener
diode or a resistor) had been scaled down to
small, inexpensive devices which could be attached to
personal computers via an RS-232 serial port. With
more and more people gaining access to the Internet
(originally mostly via dial-up to commercial Internet
Service Providers, then increasingly via persistent
broadband connections such as
ADSL
service over telephone wires or a cable television
connection), it might be possible to deploy a network of
random event generators at locations all around the world,
each of which would constantly collect timestamped data
which would be transmitted to a central server, collected
there, and made available to researchers for analysis by
whatever means they chose to apply.
As Roger Nelson discussed the project with his son Greg (who
would go on to be the principal software developer for the
project), Greg suggested that what was proposed was essentially
an
electroencephalogram
(EEG) for the hypothetical
emerging global mind, an “ElectroGaiaGram”
or EGG. Thus was born the “EGG Project” or,
as it is now formally called, the Global Consciousness
Project. Just as the many probes of an EEG provide a
(crude) view into the operation of a single brain, perhaps
the wide-flung, always-on network of REGs would pick up
evidence of coherence when a large number of the world's
minds were focused on a single event or idea. Once the
EGG project was named, terminology followed naturally: the
individual hosts running the random event generators would
be “eggs” and the central data archiving server
the “basket”.
In April 1998, Roger Nelson released the original proposal for
the project and shortly thereafter Greg Nelson began development
of the egg and basket software. I became involved in the
project in mid-summer 1998 and contributed code to the egg and
basket software, principally to allow it to be portable to other
variants of Unix systems (it was originally developed on Linux)
and machines with different byte order than the Intel processors
on which it ran, and also to reduce the resource requirements on
the egg host, making it easier to run on a non-dedicated
machine. I also contributed programs for the basket server to
assemble daily data summaries from the raw data collected by the
basket and to produce a real-time network status report. Evolved
versions of these programs remain in use today, more than two
decades later. On August 2nd, 1998, I began to run the second
egg in the network, originally on a Sun workstation running
Solaris; this was the first non-Linux, non-Intel,
big-endian egg
host in the network. A few days later, I brought up the fourth
egg, running on a Sun server in the Hall of the Servers one
floor below the second egg; this used a different kind of REG,
but was otherwise identical. Both of these eggs have been in
continuous operation from 1998 to the present (albeit with brief
outages due to power failures, machine crashes, and other
assorted disasters over the years), and have migrated from
machine to machine over time. The second egg is now connected
to Raspberry Pi running Linux, while the fourth is now hosted on
a Dell Intel-based server also running Linux, which was the
first egg host to run on a 64-bit machine in native mode.
In 1998, Roger D. Nelson, the author of this book,
realised that the rapid development and worldwide
deployment of the Internet made it possible to expand
the FieldREG concept to a global scale. Random event
generators based upon quantum effects (usually
shot
noise from tunnelling across a back-biased Zener
diode or a resistor) had been scaled down to
small, inexpensive devices which could be attached to
personal computers via an RS-232 serial port. With
more and more people gaining access to the Internet
(originally mostly via dial-up to commercial Internet
Service Providers, then increasingly via persistent
broadband connections such as
ADSL
service over telephone wires or a cable television
connection), it might be possible to deploy a network of
random event generators at locations all around the world,
each of which would constantly collect timestamped data
which would be transmitted to a central server, collected
there, and made available to researchers for analysis by
whatever means they chose to apply.
As Roger Nelson discussed the project with his son Greg (who
would go on to be the principal software developer for the
project), Greg suggested that what was proposed was essentially
an
electroencephalogram
(EEG) for the hypothetical
emerging global mind, an “ElectroGaiaGram”
or EGG. Thus was born the “EGG Project” or,
as it is now formally called, the Global Consciousness
Project. Just as the many probes of an EEG provide a
(crude) view into the operation of a single brain, perhaps
the wide-flung, always-on network of REGs would pick up
evidence of coherence when a large number of the world's
minds were focused on a single event or idea. Once the
EGG project was named, terminology followed naturally: the
individual hosts running the random event generators would
be “eggs” and the central data archiving server
the “basket”.
In April 1998, Roger Nelson released the original proposal for
the project and shortly thereafter Greg Nelson began development
of the egg and basket software. I became involved in the
project in mid-summer 1998 and contributed code to the egg and
basket software, principally to allow it to be portable to other
variants of Unix systems (it was originally developed on Linux)
and machines with different byte order than the Intel processors
on which it ran, and also to reduce the resource requirements on
the egg host, making it easier to run on a non-dedicated
machine. I also contributed programs for the basket server to
assemble daily data summaries from the raw data collected by the
basket and to produce a real-time network status report. Evolved
versions of these programs remain in use today, more than two
decades later. On August 2nd, 1998, I began to run the second
egg in the network, originally on a Sun workstation running
Solaris; this was the first non-Linux, non-Intel,
big-endian egg
host in the network. A few days later, I brought up the fourth
egg, running on a Sun server in the Hall of the Servers one
floor below the second egg; this used a different kind of REG,
but was otherwise identical. Both of these eggs have been in
continuous operation from 1998 to the present (albeit with brief
outages due to power failures, machine crashes, and other
assorted disasters over the years), and have migrated from
machine to machine over time. The second egg is now connected
to Raspberry Pi running Linux, while the fourth is now hosted on
a Dell Intel-based server also running Linux, which was the
first egg host to run on a 64-bit machine in native mode.
Here is precisely how the network measures deviation from the expectation for genuinely random data. The egg hosts all run a Network Time Protocol (NTP) client to provide accurate synchronisation with Internet time server hosts which are ultimately synchronised to atomic clocks or GPS. At the start of every second a total of 200 bits are read from the random event generator. Since all the existing generators provide eight bits of random data transmitted as bytes on a 9600 baud serial port, this involves waiting until the start of the second, reading 25 bytes from the serial port (first flushing any potentially buffered data), then breaking the eight bits out of each byte of data. A precision timing loop guarantees that the sampling starts at the beginning of the second-long interval to the accuracy of the computer's clock. This process produces 200 random bits. These bits, one or zero, are summed to produce a “sample” which counts the number of one bits for that second. This sample is stored in a buffer on the egg host, along with a timestamp (in Unix time() format), which indicates when it was taken. Buffers of completed samples are archived in files on the egg host's file system. Periodically, the basket host will contact the egg host over the Internet and request any samples collected after the last packet it received from the egg host. The egg will then transmit any newer buffers it has filled to the basket. All communications are performed over the stateless UDP Internet protocol, and the design of the basket request and egg reply protocol is robust against loss of packets or packets being received out of order. (This data transfer protocol may seem odd, but recall that the network was designed more than twenty years ago when many people, especially those outside large universities and companies, had dial-up Internet access. The architecture would allow a dial-up egg to collect data continuously and then, when it happened to be connected to the Internet, respond to a poll from the basket and transmit its accumulated data during the time it was connected. It also makes the network immune to random outages in Internet connectivity. Over two decades of operation, we have had exactly zero problems with Internet outages causing loss of data.) When a buffer from an egg host is received by the basket, it is stored in a database directory for that egg. The buffer contains a time stamp identifying the second at which each sample within it was collected. All times are stored in Universal Time (UTC), so no correction for time zones or summer and winter time is required. This is the entire collection process of the network. The basket host, which was originally located at Princeton University and now is on a server at global-mind.org, only stores buffers in the database. Buffers, once stored, are never modified by any other program. Bad data, usually long strings of zeroes or ones produced when a hardware random event generator fails electrically, are identified by a “sanity check” program and then manually added to a “rotten egg” database which causes these sequences to be ignored by analysis programs. The random event generators are very simple and rarely fail, so this is a very unusual circumstance. The raw database format is difficult for analysis programs to process, so every day an automated program (which I wrote) is run which reads the basket database, extracts every sample collected for the previous 24 hour period (or any desired 24 hour window in the history of the project), and creates a day summary file with a record for every second in the day with a column for the samples from each egg which reported that day. Missing data (eggs which did not report for that second) is indicated by a blank in that column. The data are encoded in CSV format which is easy to load into a spreadsheet or read with a program. Because some eggs may not report immediately due to Internet outages or other problems, the summary data report is re-generated two days later to capture late-arriving data. You can request custom data reports for your own analysis from the Custom Data Request page. If you are interested in doing your own exploratory analysis of the Global Consciousness Project data set, you may find my EGGSHELL C++ libraries useful. The analysis performed by the Project proceeds from these summary files as follows.First, we observe than each sample (xi) from egg i consists of 200 bits with an expected equal probability of being zero or one. Thus each sample has a mean expectation value (μ) of 100 and a standard deviation (σ) of 7.071 (which is just the square root of half the mean value in the case of events with probability 0.5).
Then, for each sample, we can compute its Stouffer Z-score as Zi = (xi −μ) / σ. From the Z-score, it is possible to directly compute the probability that the observed deviation from the expected mean value (μ) was due to chance.
It is now possible to compute a network-wide Z-score for all eggs reporting samples in that second using Stouffer's formula:
over all k eggs reporting. From this, one can compute the probability that the result from all k eggs reporting in that second was due to chance. Squaring this composite Z-score over all k eggs gives a chi-squared distributed value we shall call V, V = Z² which has one degree of freedom. These values may be summed, yielding a chi-squared distributed number with degrees of freedom equal to the number of values summed. From the chi-squared sum and number of degrees of freedom, the probability of the result over an entire period may be computed. This gives the probability that the deviation observed by all the eggs (the number of which may vary from second to second) over the selected window was due to chance. In most of the analyses of Global Consciousness Project data an analysis window of one second is used, which avoids the need for the chi-squared summing of Z-scores across multiple seconds. The most common way to visualise these data is a “cumulative deviation plot” in which the squared Z-scores are summed to show the cumulative deviation from chance expectation over time. These plots are usually accompanied by a curve which shows the boundary for a chance probability of 0.05, or one in twenty, which is often used a criterion for significance. Here is such a plot for U.S. president Obama's 2012 State of the Union address, an event of ephemeral significance which few people anticipated and even fewer remember.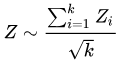
What we see here is precisely what you'd expect for purely random data without any divergence from random expectation. The cumulative deviation wanders around the expectation value of zero in a “random walk” without any obvious trend and never approaches the threshold of significance. So do all of our plots look like this (which is what you'd expect)? Well, not exactly. Now let's look at an event which was unexpected and garnered much more worldwide attention: the death of Muammar Gadaffi (or however you choose to spell it) on 2011-10-20.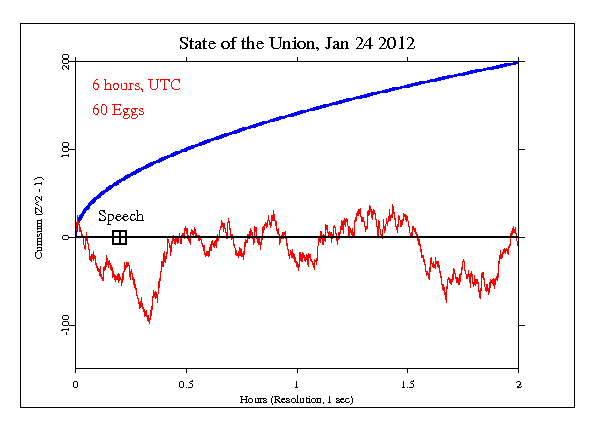
Now we see the cumulative deviation taking off, blowing right through the criterion of significance, and ending twelve hours later with a Z-score of 2.38 and a probability of the result being due to chance of one in 111. What's going on here? How could an event which engages the minds of billions of slightly-evolved apes affect the output of random event generators driven by quantum processes believed to be inherently random? Hypotheses non fingo. All, right, I'll fingo just a little bit, suggesting that my crackpot theory of paranormal phenomena might be in play here. But the real test is not in potentially cherry-picked events such as I've shown you here, but the accumulation of evidence over almost two decades. Each event has been the subject of a formal prediction, recorded in a Hypothesis Registry before the data were examined. (Some of these events were predicted well in advance [for example, New Year's Day celebrations or solar eclipses], while others could be defined only after the fact, such as terrorist attacks or earthquakes). The significance of the entire ensemble of tests can be computed from the network results from the 500 formal predictions in the Hypothesis Registry and the network results for the periods where a non-random effect was predicted. To compute this effect, we take the formal predictions and compute a cumulative Z-score across the events. Here's what you get.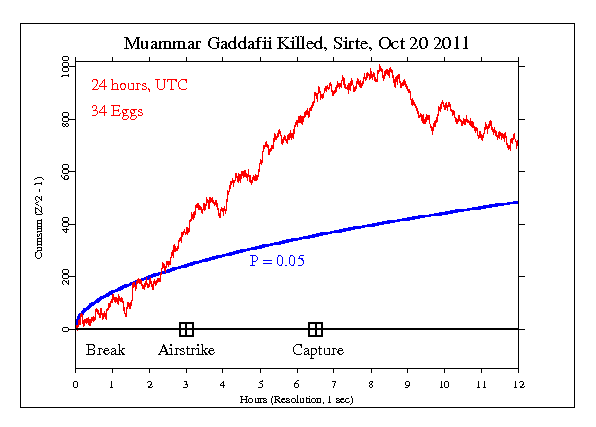
Now this is…interesting. Here, summing over 500 formal predictions, we have a Z-score of 7.31, which implies that the results observed were due to chance with a probability of less than one in a trillion. This is far beyond the criterion usually considered for a discovery in physics. And yet, what we have here is a tiny effect. But could it be expected in truly random data? To check this, we compare the results from the network for the events in the Hypothesis Registry with 500 simulated runs using data from a pseudorandom normal distribution.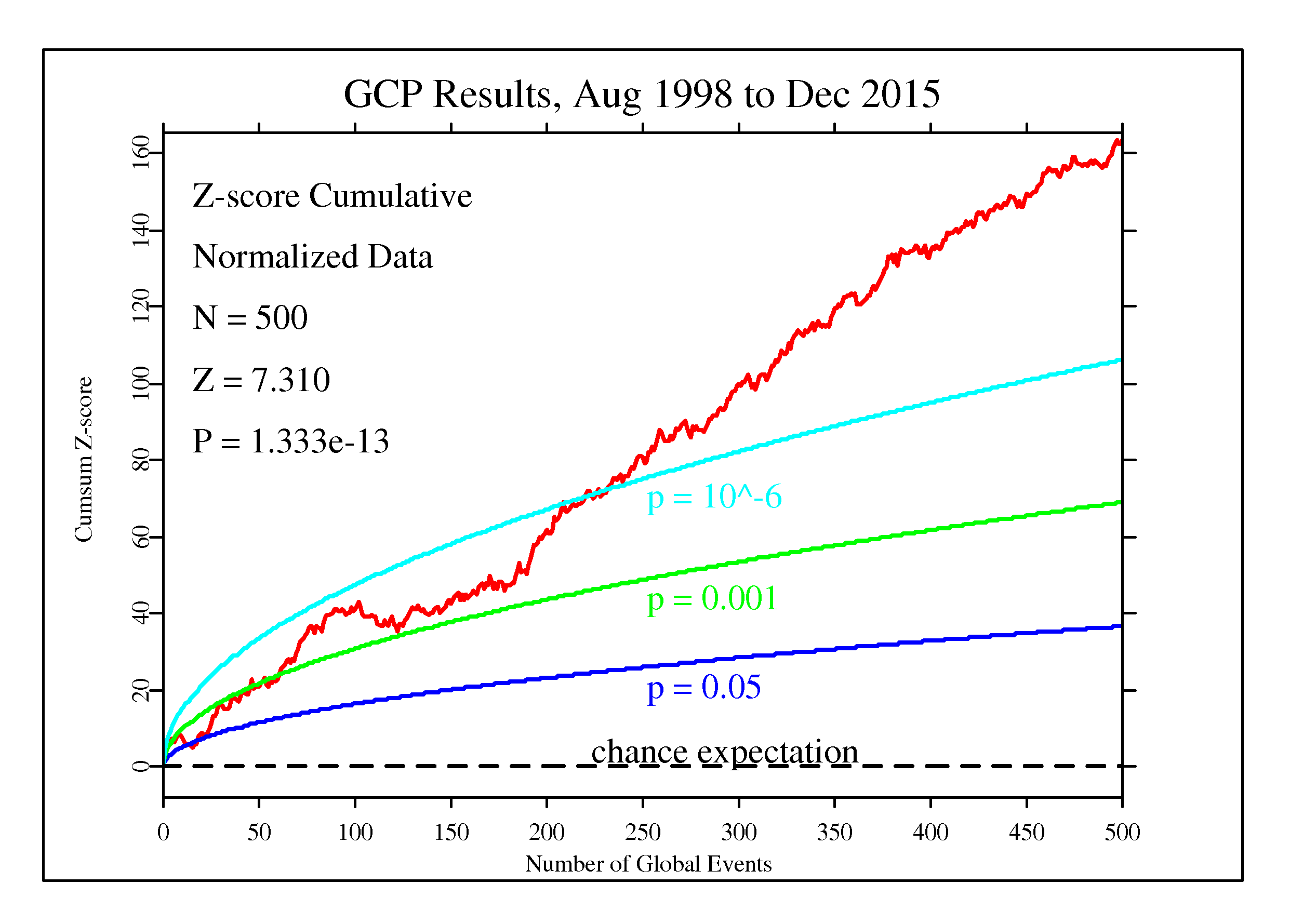
Since the network has been up and running continually since 1998, it was in operation on September 11, 2001, when a mass casualty terrorist attack occurred in the United States. The formally recorded prediction for this event was an elevated network variance in the period starting 10 minutes before the first plane crashed into the World Trade Center and extending for over four hours afterward (from 08:35 through 12:45 Eastern Daylight Time). There were 37 eggs reporting that day (around half the size of the fully built-out network at its largest). Here is a chart of the cumulative deviation of chi-square for that period.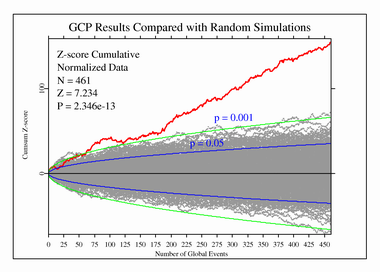
The final probability was 0.028, which is equivalent to an odds ratio of 35 to one against chance. This is not a particularly significant result, but it met the pre-specified criterion of significance of probability less than 0.05. An alternative way of looking at the data is to plot the cumulative Z-score, which shows both the direction of the deviations from expectation for randomness as well as their magnitude, and can serve as a measure of correlation among the eggs (which should not exist in genuinely random data). This and subsequent analyses did not contribute to the formal database of results from which the overall significance figures were calculated, but are rather exploratory analyses at the data to see if other interesting patterns might be present.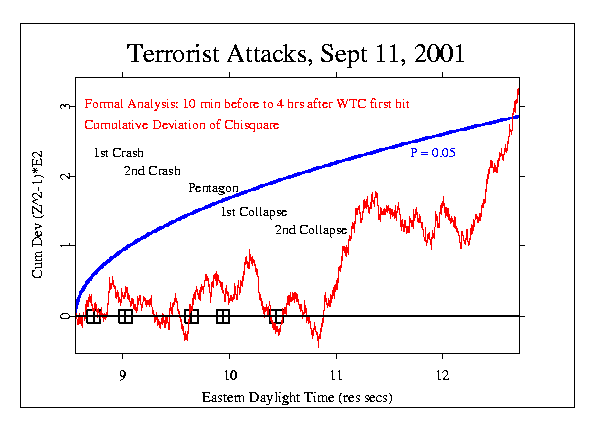
Had this form of analysis and time window been chosen a priori, it would have been calculated to have a chance probability of 0.000075, or less than one in ten thousand. Now let's look at a week-long window of time between September 7 and 13. The time of the September 11 attacks is marked by the black box. We use the cumulative deviation of chi-square from the formal analysis and start the plot of the P=0.05 envelope at that time.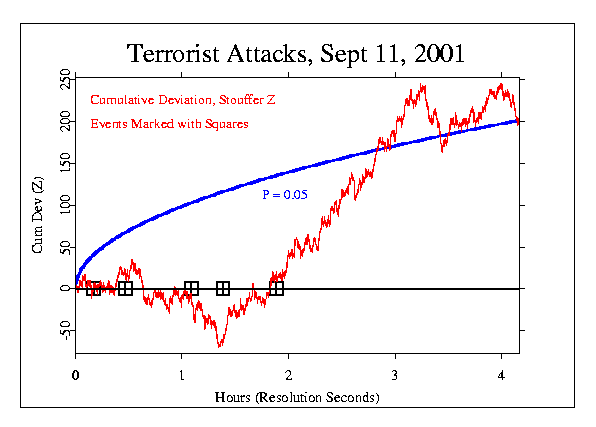
Another analysis looks at a 20 hour period centred on the attacks and smooths the Z-scores by averaging them within a one hour sliding window, then squares the average and converts to odds against chance.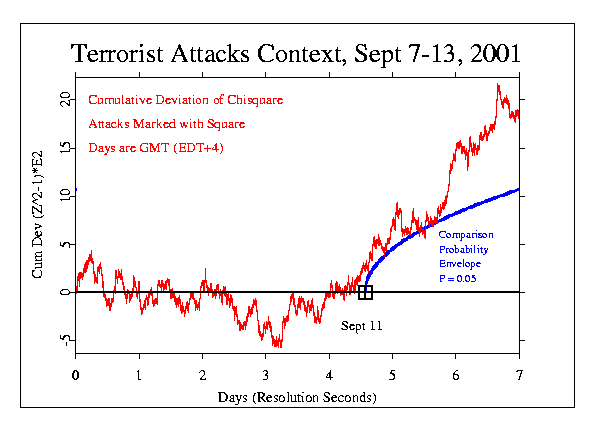
Dean Radin performed an independent analysis of the day's data binning Z-score data into five minute intervals over the period from September 6 to 13, then calculating the odds against the result being a random fluctuation. This is plotted on a logarithmic scale of odds against chance, with each 0 on the X axis denoting midnight of each day.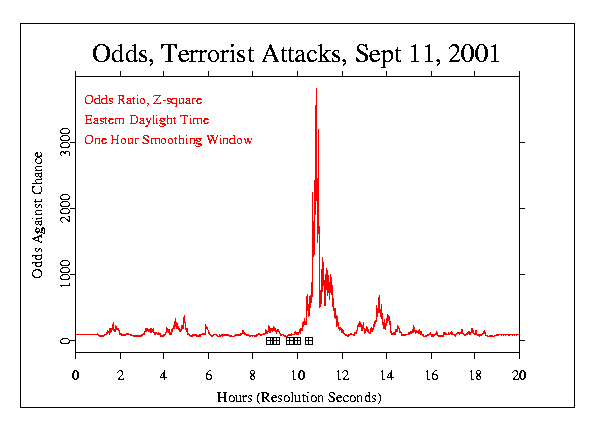
The following is the result when the actual GCP data from September 2001 is replaced with pseudorandom data for the same period.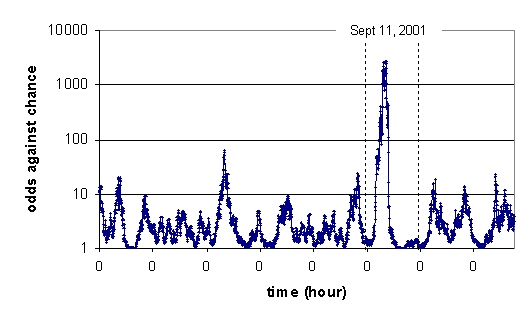
So, what are we to make of all this? That depends upon what you, and I, and everybody else make of this large body of publicly-available, transparently-collected data assembled over more than twenty years from dozens of independently-operated sites all over the world. I don't know about you, but I find it darned intriguing. Having been involved in the project since its very early days and seen all of the software used in data collection and archiving with my own eyes, I have complete confidence in the integrity of the data and the people involved with the project. The individual random event generators pass exhaustive randomness tests. When control runs are made by substituting data for the periods predicted in the formal tests with data collected at other randomly selected intervals from the actual physical network, the observed deviations from randomness go away, and the same happens when network data are replaced by computer-generated pseudorandom data. The statistics used in the formal analysis are all simple matters you'll learn in an introductory stat class and are explained in my “Introduction to Probability and Statistics”. If you're interested in exploring further, Roger Nelson's book is an excellent introduction to the rationale and history of the project, how it works, and a look at the principal results and what they might mean. There is also non-formal exploration of other possible effects, such as attenuation by distance, day and night sleep cycles, and effect sizes for different categories of events. There's also quite a bit of New Age stuff which makes my engineer's eyes glaze over, but it doesn't detract from the rigorous information elsewhere. The ultimate resource is the Global Consciousness Project's sprawling and detailed Web site. Although well-designed, the site can be somewhat intimidating due to its sheer size. You can find historical documents, complete access to the full database, analyses of events, and even the complete source code for the egg and basket programs. A Kindle edition is available. All graphs in this article are as posted on the Global Consciousness Project Web site.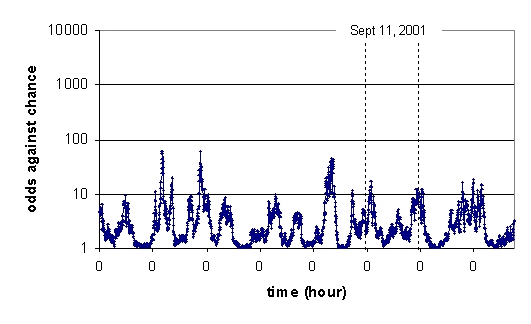
Posted at
21:10
![]()