« December 2006 | Main | February 2007 »
Tuesday, January 30, 2007
A Quarter Century Ago Today
Twenty-five years ago today, January 30th, 1982, the initial meeting to organise what became Autodesk, Inc. was held in my house in Mill Valley, California, then galactic headquarters of Marinchip Systems, Ltd. The working paper, mailed two weeks earlier, laid out the plans for the company, such as they were, and served as an invitation to the organisational meeting. The working name was “Marin Software Partners” in this paper. We showed prototypes of AutoCAD and Autodesk at the West Coast Computer Faire on March, 19th, 1982 (using a booth which Marinchip had already reserved and paid for). The brochure we handed out at the Computer Faire was the first time “Autodesk” (the product) was publicly mentioned. By then we were calling the company “Desktop Solutions” which, along with several other alternatives, was rejected by the California Secretary of State. We ended up falling back to the name of which Dan Drake wrote in Information Letter 4:“At the March 16 meeting we reached a pseudo-consensus on an unsatisfactory name for the corporation (Autodesk Inc.), …”Other twenty-fifth anniversaries this year are:
| April 26 | Incorporation of Autodesk, Inc. |
| November 24–26 | AutoCAD launch at COMDEX in Las Vegas |
Posted at
21:43
![]()
Sunday, January 28, 2007
Movable Type: XHTML 1.0 Compliant Popup Image Template
I recently updated the Fourmilab Movable Type installation to the 3.34 release. Whenever I install a new release, I modify a few representative pages and pass them through the W3C markup validator to make sure the generated documents remain compliant with the XHTML 1.0 (Transitional) standard. One potentially confusing thing about updating Movable Type is that the process of installing an update does not automatically apply any updates to the templates used by a Web log (there are gimmicky ways to set things up with templates linked to files in the default_templates directory of the distribution which can achieve this, but that has its own risks and, besides, hardly anybody does that). This is a good thing, since if you've modified one or more of the templates used to generate your Web log, you wouldn't want your changes blindly overwritten when you installed the update. But it does mean that it's wise to review the changes in the default templates between the old and new releases because there may be fixes you should integrate into your own templates. When you upload an image file, create a thumbnail for it, and specify “Popup” presentation, Movable Type creates HTML to embed a thumbnail image in the item which, when clicked, will pop up a new window that displays the full size image. This is done by linking to a little HTML document, placed in the directory with the image and thumbnail, which simply includes the image. In the process of testing such a document updated with the new release, I discovered that the rudimentary HTML which wraps the full size image fails validation with 8 errors among which are the absence of a character set specification, missing DOCTYPE, absence of a “<head>” section, no “alt=” specification for the image, and browser-specific margin specifications in the “<body>” tag. I initially assumed this was due to an obsolete template being used for these documents but when I checked, it turned out that the default template in question, “default_templates/uploaded_image_popup_template.tmpl” in the Movable Type 3.34 distribution, still prescribed the generation of such documents. I created a new template which generates XHTML 1.0 compliant popup image documents which the validator accepts without errors or warnings. If you'd like to implement this fix on your Movable Type installation, download the zipped archive, extract the file fourmilab_uploaded_image_popup_template.tmpl, and replace your current “Uploaded Image Popup Template” (found under the System tab of the Templates configuration page) with the contents of this file. After saving the changed template, be sure to try uploading a popup image with a thumbnail and make sure everything is working properly. If you wish to revert to the standard configuration, you can replace the modified template with the contents of the default_templates/uploaded_image_popup_template.tmpl distribution file. Note that installing this template will only affect images you subsequently upload; if you have existing popup image documents which you wish to pass validation, you'll need to manually modify them individually. Unlike a change to an Index or Archive template, which can be applied to all documents simply by rebuilding the site, this System template only runs once when you actually upload the image.Posted at
20:34
![]()
Saturday, January 27, 2007
Reading List: Empire
- Card, Orson Scott. Empire. New York: Tor, 2006. ISBN 0-7653-1611-0.
-
I first heard of this novel in an
Instapundit
podcast interview with the author, with whom I was familiar,
having read and admired Ender's Game when
it first appeared in 1977 as a novelette in Analog (it was later expanded
and published as a novel in 1985) and several of his books since then. I'd
always pigeonholed him as a science fictioneer, so I was somewhat surprised
to learn that his latest effort was a techno-thriller in the Tom Clancy vein,
with the flabbergasting premise of a near future American civil war
pitting the conservative “red states” against the liberal “blue
states”. The interview, which largely stayed away from the book, was
interesting and since I'd never felt let down by any of Card's previous work (although
none of it that I'd read seemed to come up to the level of Ender's Game,
but then I've read only a fraction of his prolific output), I decided to give
it a try.
Spoiler warning: Plot and/or ending details follow.The story is set in the very near future: a Republican president detested by the left and reviled in the media is in the White House, the Republican nomination for his successor is a toss-up, and a ruthless woman is the Democratic front-runner. In fact, unless this is an alternative universe with a different calendar, we can identify the year as 2008, since that's the only presidential election year on which June 13th falls on a Friday until 2036, by which date it's unlikely Bill O'Reilly will still be on the air. The book starts out with a bang and proceeds as a tautly-plotted, edge of the seat thriller which I found more compelling than any of Clancy's recent doorstop specials. Then, halfway through chapter 11, things go all weird. It's like the author was holding his breath and chanting the mantra “no science fiction—no science fiction” and then just couldn't take it any more, explosively exhaled, drew a deep breath, and furiously started pounding the keys. (This is not, in fact, what happened, but we don't find that out until the end material, which I'll describe below.) Anyway, everything is developing as a near-future thriller combined with a “who do you trust” story of intrigue, and then suddenly, on p. 157, our heroes run into two-legged robotic Star Wars-like imperial walkers on the streets of Manhattan and, before long, storm troopers in space helmets and body armour, death rays that shoot down fighter jets, and later, “hovercycles”—yikes. We eventually end up at a Bond villain redoubt in Washington State built by a mad collectivist billionaire clearly patterned on George Soros, for a final battle in which a small band of former Special Ops heroes take on all of the villains and their futuristic weaponry by grit and guile. If you like this kind of stuff, you'll probably like this. The author lost me with the imperial walkers, and it has nothing to do with my last name, or my anarchist proclivities. May we do a little physics here? Let's take a closer look at the lair of the evil genius, hidden under a reservoir formed by a boondoggle hydroelectric dam “near Highway 12 between Mount St. Helens and Mount Rainier” (p. 350). We're told (p. 282) that the entry to the facility is hidden beneath the surface of the lake formed in a canyon behind a dam, and access to it is provided by pumping water from the lake to another, smaller lake in an adjacent canyon. The smaller lake is said to be two miles long, and exposing the entrance to the rebels' headquarters causes the water to rise fifteen feet in that lake. The width of the smaller lake is never given, but most of the natural lakes in that region seem to be long and skinny, so let's guess it's only a tenth as wide as it is long, or about 300 yards wide. The smaller lake is said to be above the lake which conceals the entrance, so to expose the door would require pumping a chunk of water we can roughly estimate (assuming the canyon is rectangular) at 2 miles by 300 yards by fifteen feet. Transforming all of these imperial (there's that word again!) measures into something comprehensible, we can compute the volume of water as about 4 million cubic metres or, as the boots on the ground would probably put it, about a billion gallons. This is a lot of water. A cubic metre of water weighs 1000 kg, or a metric ton, so in order to expose the door, the villains would have to pump 4 billion kilograms of water uphill at least 15 feet (because the smaller lake is sufficiently above the facility to allow it to be flooded [p. 308] it would almost certainly be much more, but let's be conservative)—call it 5 metres. Now the energy required to raise this quantity of water 5 metres against the Earth's gravitation is just the product of the mass (4 billion kilograms), the distance (5 metres), and gravitational acceleration of 9.8 m/s², which works out to about 200 billion joules, or 54 megawatt-hours. If the height difference were double our estimate, double these numbers. Now to pump all of that water uphill in, say, half an hour (which seems longer than the interval in which it happens on pp. 288–308) will require about 100 megawatts of power, and that's assuming the pumps are 100% efficient and there are no frictional losses in the pipes. Where does the power come from? It can't come from the hydroelectric dam, since in order to generate the power to pump the water, you'd need to run a comparable amount of water through the dam's turbines (less because the drop would be greater, but then you have to figure in the efficiency of the turbines and generators, which is about 80%), and we've already been told that dumping the water over the dam would flood communities in the valley floor. If they could store the energy from letting the water back into the lower lake, then they could re-use it (less losses) to pump it back uphill again, but there's no way to store anything like that kind of energy—in fact, pumping water uphill and releasing it through turbines is the only practical way to store large quantities of electricity, and once the water is in the lower lake, there's no place to put the power. We've already established that there are no heavy duty power lines running to the area, as that would be immediately suspicious (of course, it's also suspicious that there aren't high tension lines running from what's supposed to be a hydroelectric dam, but that's another matter). And if the evil genius had invented a way to efficiently store and release power on that scale, he wouldn't need to start a civil war—he could just about buy the government with the proceeds from such an invention.Call me picky—“You're picky!”—feel better now?—but I just cannot let this go unremarked. On p. 248, one character likens another to Hari Seldon in Isaac Asimov's Foundation novels. But it's spelt “Hari Selden”, and it's not a typo because the name is given the same wrong way three times on the same page! Now I'd excuse such a goof by a thriller scribbler recalling science fiction he'd read as a kid, but this guy is a distinguished science fiction writer who has won the Hugo Award—four times, and this book is published by Tor Books, the pre-eminent specialist science fiction press; don't they have an editor on staff who's familiar with one of the universally acknowledged classics of the genre and winner of the unique Hugo for Best All-Time Series? One becomes accustomed to low expectations for science fiction novel cover art, but expects a slightly higher standard for techno-thrillers. The image on the dust jacket has absolutely nothing whatsoever to do with any scene in the book. It looks like a re-mix of several thriller covers chosen at random. It is only on p. 341, in the afterword, that we learn this novel was commissioned as part of a project to create an “entertainment franchise”, and on p. 349, in the acknowledgements, that this is, in fact, the scenario of a video game already under development when the author joined the team. Frankly, it shows. As befits the founding document of an “entertainment franchise” the story ends setting the stage for the sequel, although at least to this reader, the plot for the first third of that work seems transparently obvious, but then Card is a master of the gob smack switcheroo, as the present work demonstrates. In any case, what we have here appears to be Volume One of a series of alternative future political/military novels like Allen Drury's Advise and Consent series. While that novel won a Pulitzer Prize, the sequels rapidly degenerated into shrill right-wing screeds. In Empire Card is reasonably even-handed, although his heterodox personal views are apparent. I hope the inevitable sequels come up to that standard, but I doubt I'll be reading them.Spoilers end here.
Posted at
22:23
![]()
Tuesday, January 23, 2007
Reading List: Time to Emigrate?
- Walden, George. Time to Emigrate? London: Gibson Square, 2006. ISBN 1-903933-93-5.
- Readers of Theodore Dalrymple's Life at the Bottom and Our Culture, What's Left of It may have thought his dire view of the state of civilisation in Britain to have been unduly influenced by his perspective as a prison and public hospital physician in one of the toughest areas of Birmingham, England. Here we have, if not the “view from the top”, a brutally candid evaluation written by a former Minister of Higher Education in the Thatcher government and Conservative member of the House of Commons from 1983 until his retirement in 1997, and it is, if anything, more disturbing. The author says of himself (p. 219), “My life began unpromisingly, but everything's always got better. … In other words, in personal terms I've absolutely no complaints.” But he is deeply worried about whether his grown children and their children can have the same expectations in the Britain of today and tomorrow. The book is written in the form of a long (224 page) and somewhat rambling letter to a fictional son and his wife who are pondering emigrating from Britain after their young son was beaten into unconsciousness by immigrants within sight of their house in London. He describes his estimation of the culture, politics, and economy of Britain as much like the work of a house surveyor: trying to anticipate the problems which may befall those who choose to live there. Wherever he looks: immigration, multiculturalism, education, transportation, the increasingly debt-supported consumer economy, public health services, mass media, and the state of political discourse, he finds much to fret about. But this does not come across as the sputtering of an ageing Tory, but rather a thoroughly documented account of how most of the things which the British have traditionally valued (and have attracted immigrants to their shores) have eroded during his lifetime, to such an extent that he can no longer believe that his children and grandchildren will have the same opportunities he had as a lower middle class boy born twelve days after Britain declared war on Germany in 1939. The curious thing about emigration from the British Isles today is that it's the middle class that is bailing out. Over most of history, it was the lower classes seeking opportunity (or in the case of my Irish ancestors, simply survival) on foreign shores, and the surplus sons of the privileged classes hoping to found their own dynasties in the colonies. But now, it's the middle that's being squeezed out, and it's because the collectivist state is squeezing them for all they're worth. The inexorably growing native underclass and immigrants benefit from government services and either don't have the option to leave or else consider their lot in life in Britain far better than whence they came. The upper classes can opt out of the sordid shoddiness and endless grey queues of socialism; on p. 153 the author works out the cost: for a notional family of two parents and two children, “going private” for health care, education for the kids, transportation, and moving to a “safe neighbourhood” would roughly require doubling income from what such a typical family brings home. Is it any wonder we have so many billionaire collectivists (Buffett, Gates, Soros, etc.)? They don't have to experience the sordid consequences of their policies, but by advocating them, they can recruit the underclass (who benefit from them and are eventually made dependent and unable to escape from helotry) to vote them into power and keep them there. And they can exult in virtue as their noble policies crush those who might aspire to their own exalted station. The middle class, who pay for all of this, forced into minority, retains only the franchise which is exercised through shoe leather on pavement, and begins to get out while the property market remains booming and the doors are still open. The author is anything but a doctrinaire Tory; he has, in fact, quit the party, and savages its present “100% Feck-Free” (my term) leader, David Cameron as, among other things, a “transexualised [Princess] Diana” (p. 218). As an emigrant myself, albeit from a different country, I think his conclusion and final recommendation couldn't be wiser (and I'm sorry if this is a spoiler, but if you're considering such a course you should read this book cover to cover anyway): go live somewhere else (I'd say, anywhere else) and see how you like it. You may discover that you're obsessed with what you miss and join the “International Club” (which usually means the place they speak the language of the Old Country), or you may find that after struggling with language, customs, and how things are done, you fit in rather well and, after a while, find most of your nightmares are about things in the place you left instead of the one you worried about moving to. There's no way to know—it could go either way. I think the author, as many people, may have put somewhat more weight on the question of emigration that it deserves. I've always looked at countries like any other product. I've never accepted that because I happened to be born within the borders of some state to whose creation and legitimacy I never personally consented, that I owe it any obligation whatsoever apart from those in compensation for services provided directly to me with my assent. Quitting Tyrania to live in Freedonia is something anybody should be able do to, assuming the residents of Freedonia welcome you, and it shouldn't occasion any more soul-searching on the part of the emigrant than somebody choosing to trade in their VW bus for a Nissan econobox because the 1972 bus was a shoddy crapwagon. Yes, you should worry and even lose sleep over all the changes you'll have to make, but there's no reason to gum up an already difficult decision process by cranking all kinds of guilt into it. Nobody (well, nobody remotely sane) gets all consumed by questions of allegiance, loyalty, or heritage when deciding whether their next computer will run Windows, MacOS, Linux, or FreeBSD. It seems to me that once you step back from the flags and anthems and monuments and kings and presidents and prime ministers and all of the other atavistic baggage of the coercive state, it's wisest to look at your polity like an operating system; it's something that you have to deal with (increasingly, as the incessant collectivist ratchet tightens the garrote around individuality and productivity), but you still have a choice among them, and given how short is our tenure on this planet, we shouldn't waste a moment of it living somewhere that callously exploits our labours in the interest of others. And, the more productive people exercise that choice, the greater the incentive is for the self-styled rulers of the various states to create an environment which will attract people like ourselves. Many of the same issues are discussed, from a broader European perspective, in Claire Berlinski's Menace in Europe and Mark Steyn's America Alone. To fend off queries, I emigrated from what many consider the immigration magnet of the world in 1991 and have never looked back and rarely even visited the old country except for business and family obligations. But then I suspect, as the author notes on p. 197, I am one of those D4-7 allele people (look it up!) who thrive on risk and novelty; I'm not remotely claiming that this is better—Heaven knows we DRD4 7-repeat folk have caused more than our cohort's proportion of chaos and mayhem, but we just can't give it up—this is who we are.
Posted at
01:31
![]()
Thursday, January 18, 2007
Reading List: Gunpowder
- Ponting, Clive. Gunpowder. London: Pimlico, 2005. ISBN 1-84413-543-8.
- When I was a kid, we learnt in history class that gunpowder had been discovered in the thirteenth century by the English Franciscan monk Roger Bacon, who is considered one of the founders of Western science. The Chinese were also said to have known of gunpowder, but used it only for fireworks, as opposed to the applications in the fields of murder and mayhem the more clever Europeans quickly devised. In The Happy Turning, H. G. Wells remarked that “truth has a way of heaving up through the cracks of history”, and so it has been with the origin of gunpowder, as recounted here. It is one of those splendid ironies that gunpowder, which, along with its more recent successors, has contributed to the slaughter of more human beings than any other invention with the exception of government, was discovered in the 9th century A.D. by Taoist alchemists in China who were searching for an elixir of immortality (and, in fact, gunpowder continued to be used as a medicine in China for centuries thereafter). But almost as soon as the explosive potential of gunpowder was discovered, the Chinese began to apply it to weapons and, over the next couple of centuries had invented essentially every kind of firearm and explosive weapon which exists today. Gunpowder is not a high explosive; it does not detonate in a supersonic shock wave as do substances such as nitroglycerine and TNT, but rather deflagrates, or burns rapidly, as the heat of combustion causes the release of the oxygen in the nitrate compound in the mix. If confined, of course, the rapid release of gases and heat can cause a container to explode, but the rapid combustion of gunpowder also makes it suitable as a propellant in guns and rockets. The early Chinese formulations used a relatively small amount of saltpetre (potassium nitrate), and were used in incendiary weapons such as fire arrows, fire lances (a kind of flamethrower), and incendiary bombs launched by catapults and trebuchets. Eventually the Chinese developed high-nitrate mixes which could be used in explosive bombs, rockets, guns, and cannon (which were perfected in China long before the West, where the technology of casting iron did not appear until two thousand years after it was known in China). From China, gunpowder technology spread to the Islamic world, where bombardment by a giant cannon contributed to the fall of Constantinople to the Ottoman Empire. Knowledge of gunpowder almost certainly reached Europe via contact with the Islamic invaders of Spain. The first known European document giving its formula, whose disarmingly candid Latin title Liber Ignium ad Comburendos Hostes translates to “Book of Fires for the Burning of Enemies”, dates from about 1300 and contains a number of untranslated Arabic words. Gunpowder weapons soon became a fixture of European warfare, but crude gun fabrication and weak powder formulations initially limited their use mostly to huge siege cannons which launched large stone projectiles against fortifications at low velocity. But as weapon designs and the strength of powder improved, the balance in siege warfare shifted from the defender to the attacker, and the consolidation of power in Europe began to accelerate. The author argues persuasively that gunpowder played an essential part in the emergence of the modern European state, because the infrastructure needed to produce saltpetre, manufacture gunpowder weapons in quantity, equip, train, and pay ever-larger standing armies required a centralised administration with intrusive taxation and regulation which did not exist before. Once these institutions were in place, they conferred such a strategic advantage that the ruler was able to consolidate and expand the area of control at the expense of previously autonomous regions, until coming up against another such “gunpowder state”. Certainly it was gunpowder weapons which enabled Europeans to conquer colonies around the globe and eventually impose their will on China, where centuries of political stability had caused weapons technology to stagnate by comparison with that of conflict-ridden Europe. It was not until the nineteenth century that other explosives and propellants discovered by European chemists brought the millennium-long era of gunpowder a close. Gunpowder shaped human history as have few other inventions. This excellent book recounts that story from gunpowder's accidental invention as an elixir to its replacement by even more destructive substances, and provides a perspective on a thousand years of world history in terms of the weapons with which so much of it was created.
Posted at
16:15
![]()
Wednesday, January 17, 2007
Your Sky Updated
I have just put a new version of Your Sky into production. This release includes all of the Unix process fork optimisation and security improvements earlier implemented in Earth and Moon Viewer and Solar System Live, and upgrades the documentation to use Unicode text elements for opening and closing quotes, dashes, and minus signs. A consistent CSS style sheet is now applied to all of the documents, which remain XHTML 1.0 (Transitional) compliant. This release should be 100% compatible with existing URLs which reference it; if you find one that's broken, please let me know with the Feedback button. I'll be keeping an eye on the Apache error log for the next few days to look for gross pratfalls, but if you spot more subtle goofs I'd very much appreciate your pointing them out. Thanks in advance. If you do have direct links on your site to Your Sky result pages or dynamic image requests, consider removing the now-unnecessary (but harmless) “/uncgi” from the URLs; eliminating this step reduces the load on the server and (probably imperceptibly) speeds up response to the request.Posted at
17:07
![]()
Saturday, January 13, 2007
Reading List: Sister Bernadette's Barking Dog
- Florey, Kitty Burns. Sister Bernadette's Barking Dog. Hoboken, NJ: Melville House, 2006. ISBN 1-933633-10-7.
-
In 1877, Alonzo Reed and and Brainerd Kellogg published Higher
Lessons in English, which introduced their system for the
grammatical diagramming of English sentences. For example, the
sentence “When my father and my mother forsake me, then the Lord
will take me up” (an example from Lesson 63 of their book)
would be diagrammed as:
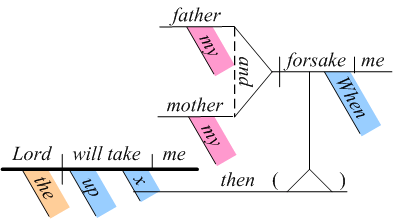
Diagram by Bruce D. Despain.
Posted at
22:44
![]()
Friday, January 12, 2007
Two Pineapple Grenades
You know how it goes: you're making dinner and suddenly discover you're missing some essential ingredient you always have plenty of. You start frantically searching the top and bottom shelves of the pantry, all the way to the back, mumbling to yourself, “We just can't have run out of pickled pig snouts!” And then you see it. Not what you were looking for, to be sure, but it, that item that's been sitting there for so long you've completely forgotten when you bought it or why. You look at the “best by” date and suddenly it comes home to you that you're getting old and have lived in one place for what would have seemed a lifetime in your youth. And then you wonder if it's still good.
Well, in this case, the answer to that last question is pretty obvious. In fact, I was a little hesitant to pick this one up to check the expiration date for fear it would blow up in my hand.
The Mk II fragmentation hand grenade used by the U.S. military from World War II through the start of the Vietnam War was often called a “pineapple grenade” due to its shape and the grooves moulded into its surface. Well, here, right on my pantry shelf, was a real pineapple grenade!
According to the stamp on the lid (which you can read if you click the image to enlarge it), the contents of this can would be “best if eaten by” December 1999. Given the shelf life claimed for such canned products, it's probably been sitting on that shelf for about a decade. I haven't seen anything quite so scary-looking around the house since I extracted the grotesquely distended batteries from a UPS which was in the midst of melting down.
The frag at the left is an inert training grenade which, unlike the can of pineapple, is at no risk of exploding. Now, all I need is to get some decade-old cottage cheese to mix with the pineapple—yum!
And then you see it. Not what you were looking for, to be sure, but it, that item that's been sitting there for so long you've completely forgotten when you bought it or why. You look at the “best by” date and suddenly it comes home to you that you're getting old and have lived in one place for what would have seemed a lifetime in your youth. And then you wonder if it's still good.
Well, in this case, the answer to that last question is pretty obvious. In fact, I was a little hesitant to pick this one up to check the expiration date for fear it would blow up in my hand.
The Mk II fragmentation hand grenade used by the U.S. military from World War II through the start of the Vietnam War was often called a “pineapple grenade” due to its shape and the grooves moulded into its surface. Well, here, right on my pantry shelf, was a real pineapple grenade!
According to the stamp on the lid (which you can read if you click the image to enlarge it), the contents of this can would be “best if eaten by” December 1999. Given the shelf life claimed for such canned products, it's probably been sitting on that shelf for about a decade. I haven't seen anything quite so scary-looking around the house since I extracted the grotesquely distended batteries from a UPS which was in the midst of melting down.
The frag at the left is an inert training grenade which, unlike the can of pineapple, is at no risk of exploding. Now, all I need is to get some decade-old cottage cheese to mix with the pineapple—yum!
Posted at
20:28
![]()
Thursday, January 11, 2007
Reading List: Unknown Quantity
- Derbyshire, John. Unknown Quantity. Washington: Joseph Henry Press, 2006. ISBN 0-309-09657-X.
-
After exploring a renowned mathematical conundrum (the
Riemann
Hypothesis) in all its profundity in
Prime Obsession, in this book the author recounts
the history of algebra—an intellectual quest sprawling
over most of recorded human history and occupying some
of the greatest minds our species has produced.
Babylonian cuneiform tablets
dating from the time of
Hammurabi, about 3800 years ago,
demonstrate solving quadratic equations, extracting square
roots, and finding
Pythagorean
triples. (The methods in the Babylonian texts are recognisably
algebraic but are expressed as “word problems” instead of
algebraic notation.)
Diophantus,
about 2000 years later, was the first to write equations in
a symbolic form, but this was promptly forgotten. In fact,
twenty-six centuries after the Babylonians were solving quadratic
equations expressed in word problems,
al-Khwārizmī
(the word “algebra” is derived from the title of his
book,
الكتاب المختصر في حساب الجبر والمقابلة and “algorithm” from his name) was solving quadratic equations in word problems. It wasn't until around 1600 that anything resembling the literal symbolism of modern algebra came into use, and it took an intellect of the calibre of René Descartes to perfect it. Finally, equipped with an expressive notation, rules for symbolic manipulation, and the slowly dawning realisation that this, not numbers or geometric figures, is ultimately what mathematics is about, mathematicians embarked on a spiral of abstraction, discovery, and generalisation which has never ceased to accelerate in the centuries since. As more and more mathematics was discovered (or, if you're an anti-Platonist, invented), deep and unexpected connections were found among topics once considered unrelated, and this is a large part of the story told here, as algebra has “infiltrated” geometry, topology, number theory, and a host of other mathematical fields while, in the form of algebraic geometry and group theory, providing the foundation upon which the most fundamental theories of modern physics are built. With all of these connections, there's a strong temptation for an author to wander off into fields not generally considered part of algebra (for example, analysis or set theory); Derbyshire is admirable in his ability to stay on topic, while not shortchanging the reader where important cross-overs occur. In a book of this kind, especially one covering such a long span of history and a topic so broad, it is difficult to strike the right balance between explaining the mathematics and sketching the lives of the people who did it, and between a historical narrative and one which follows the evolution of specific ideas over time. In the opinion of this reader, Derbyshire's judgement on these matters is impeccable. As implausible as it may seem to some that a book about algebra could aspire to such a distinction, I found this one of the more compelling page-turners I've read in recent months. Six “math primers” interspersed in the text provide the fundamentals the reader needs to understand the chapters which follow. While excellent refreshers, readers who have never encountered these concepts before may find the primers difficult to comprehend (but then, they probably won't be reading a history of algebra in the first place). Thirty pages of end notes not only cite sources but expand, sometimes at substantial length, upon the main text; readers should not deprive themselves this valuable lagniappe.
al-Kitāb al-mukhtaṣar fī ḥisāb al-jabr wa-l-muqābala,
Posted at
00:21
![]()
Wednesday, January 10, 2007
The Relativity of Simultaneity Posted
I have just posted a little project I've had in mind for some time, The Relativity of Simultaneity, which demonstrates how observers separated in space, even if not moving with respect to one another, may perceive events to occur in a different order; simultaneity depends upon your vantage point. It takes light more than a second and a quarter to traverse the distance between the Earth and the Moon, which means that when you listen to recordings of Apollo Moon mission communications made on Earth, you're hearing transmissions from the Earth as they were sent, but the audio received from the Moon with a substantial delay; what the astronauts on board heard was different. In this document, I've taken a recording of the Apollo 11 Moon landing, extracted transmissions from the Earth and Moon onto separate audio tracks, and time-shifted the Earth transmissions so they occur as heard on the Moon. In addition, I have mixed in a few remarks during the landing sequence by Neil Armstrong which were captured by an on-board tape recorder in the lunar module but not transmitted to Earth. The result is an approximation of what the astronauts heard in the cabin during the descent and landing, and provides an insight into the cadence of Armstrong's first radio transmission after the touchdown. The animation in this document was created by a Perl program invoking various Netpbm utilities, then assembled into an animated GIF with Gifsicle. In the process of making the illustration, I ran into a bug in the Netpbm program ppmdraw, present at least since version 10.35.05 (the current release for the Fedora Core 6 Linux distribution) which caused it to crash due to a reference through a pointer in a previously released buffer when the script contained two or more commands. I have fixed this problem and submitted a patch to the Netpbm developers, but if you need the patch you can get it here.Posted at
18:04
![]()
Saturday, January 6, 2007
Reading List: Before The Dawn
- Wade, Nicholas. Before The Dawn. New York: Penguin Press, 2006. ISBN 1-59420-079-3.
- Modern human beings, physically very similar to people alive today, with spoken language and social institutions including religion, trade, and warfare, had evolved by 50,000 years ago, yet written historical records go back only about 5,000 years. Ninety percent of human history, then, is “prehistory” which paleoanthropologists have attempted to decipher from meagre artefacts and rare discoveries of human remains. The degree of inference and the latitude for interpretation of this material has rendered conclusions drawn from it highly speculative and tentative. But in the last decade this has begun to change. While humans only began to write the history of their species in the last 10% of their presence on the planet, the DNA that makes them human has been patiently recording their history in a robust molecular medium which only recently, with the ability to determine the sequence of the genome, humans have learnt to read. This has provided a new, largely objective, window on human history and origins, and has both confirmed results teased out of the archæological record over the centuries, and yielded a series of stunning surprises which are probably only the first of many to come. Each individual's genome is a mix of genes inherited from their father and mother, plus a few random changes (mutations) due to errors in the process of transcription. The separate genome of the mitochondria (energy producing organelles) in their cells is inherited exclusively from the mother, and in males, the Y chromosome (except for the very tips) is inherited directly from the father, unmodified except for mutations. In an isolated population whose members breed mostly with one another, members of the group will come to share a genetic signature which reflects natural selection for reproductive success in the environment they inhabit (climate, sources of food, endemic diseases, competition with other populations, etc.) and the effects of random “genetic drift” which acts to reduce genetic diversity, particularly in small, isolated populations. Random mutations appear in certain parts of the genome at a reasonably constant rate, which allows them to be used as a “molecular clock” to estimate the time elapsed since two related populations diverged from their last common ancestor. (This is biology, so naturally the details are fantastically complicated, messy, subtle, and difficult to apply in practice, but the general outline is as described above.) Even without access to the genomes of long-dead ancestors (which are difficult in the extreme to obtain and fraught with potential sources of error), the genomes of current populations provide a record of their ancestry, geographical origin, migrations, conquests and subjugations, isolation or intermarriage, diseases and disasters, population booms and busts, sources of food, and, by inference, language, social structure, and technologies. This book provides a look at the current state of research in the rapidly expanding field of genetic anthropology, and it makes for an absolutely compelling narrative of the human adventure. Obviously, in a work where the overwhelming majority of source citations are to work published in the last decade, this is a description of work in progress and most of the deductions made should be considered tentative pending further results. Genomic investigation has shed light on puzzles as varied as the size of the initial population of modern humans who left Africa (almost certainly less than 1000, and possibly a single hunter-gatherer band of about 150), the date when wolves were domesticated into dogs and where it happened, the origin of wheat and rice farming, the domestication of cattle, the origin of surnames in England, and the genetic heritage of the randiest conqueror in human history, Genghis Khan, who, based on Y chromosome analysis, appears to have about 16 million living male descendants today. Some of the results from molecular anthropology run the risk of being so at variance with the politically correct ideology of academic soft science that the author, a New York Times reporter, tiptoes around them with the mastery of prose which on other topics he deploys toward their elucidation. Chief among these is the discussion of the microcephalin and ASPM genes on pp. 97–99. (Note that genes are often named based on syndromes which result from deleterious mutations within them, and hence bear names opposite to their function in the normal organism. For example, the gene which triggers the cascade of eye formation in Drosophila is named eyeless.) Both of these genes appear to regulate brain size and, in particular, the development of the cerebral cortex, which is the site of higher intelligence in mammals. Specific alleles of these genes are of recent origin, and are unequally distributed geographically among the human population. Haplogroup D of Microcephalin appeared in the human population around 37,000 years ago (all of these estimates have a large margin of error); which is just about the time when quintessentially modern human behaviour such as cave painting appeared in Europe. Today, about 70% of the population of Europe and East Asia carry this allele, but its incidence in populations in sub-Saharan Africa ranges from 0 to 25%. The ASPM gene exists in two forms: a “new” allele which arose only about 5800 years ago (coincidentally[?] just about the time when cities, agriculture, and written language appeared), and an “old” form which predates this period. Today, the new allele occurs in about 50% of the population of the Middle East and Europe, but hardly at all in sub-Saharan Africa. Draw your own conclusions from this about the potential impact on human history when germline gene therapy becomes possible, and why opposition to it may not be the obvious ethical choice.
Posted at
22:10
![]()
Wednesday, January 3, 2007
Google PageRank Query Utility
I have just posted PageRank, a Perl program which allows the Google™ PageRank™ of Web pages to be queried, either from the command line or via an HTML query form submitted to a CGI application installed on a Web server. In addition, the program can generate a graphical page rank meter showing the ranking of the page containing it or that of an arbitrary page specified by URL. Here, for example, is the current page rank of the www.fourmilab.ch site:Posted at
15:00
![]()