Computing
- Albrecht, Katherine and Liz McIntyre. Spychips. Nashville: Nelson Current, 2005. ISBN 0-452-28766-9.
-
Imagine a world in which every manufactured object, and even living
creatures such as pets, livestock, and eventually people, had an embedded tag
with a unique 96-bit code which uniquely identified it among all
macroscopic objects on the planet and beyond. Further, imagine that
these tiny, unobtrusive and non-invasive tags could be interrogated
remotely, at a distance of up to several metres, by safe radio
frequency queries which would provide power for them to transmit
their identity. What could you do with this? Well, a heck of a lot.
Imagine, for example, a refrigerator which sensed its entire contents, and
was able to automatically place an order on the Internet for home delivery
of whatever was running short, or warned you that the item you'd just
picked up had passed its expiration date. Or think about breezing
past the checkout counter at the Mall-Mart with a cart full of stuff without
even slowing down—all of the goods would be identified by the portal
at the door, and the total charged to the account designated by the
tag in your customer fidelity card. When you're shopping, you could be
automatically warned when you pick up a product which contains an
ingredient to which you or a member of your family is allergic. And if
a product is recalled, you'll be able to instantly determine whether
you have one of the affected items, if your refrigerator or smart
medicine cabinet hasn't already done so. The benefits just go on
and on…imagine.
This is the vision of an “Internet of Things”, in which all tangible
objects are, in a real sense, on-line in real-time, with their position and
status updated by ubiquitous and networked sensors. This is not a utopian
vision. In 1994 I sketched Unicard, a
unified personal identity document, and explored its consequences; people
laughed: “never happen”. But just five years later, the
Auto-ID Labs were formed at MIT, dedicated
to developing a far more ubiquitous identification technology. With the support
of major companies such as Procter & Gamble, Philip Morris, Wal-Mart,
Gillette, and IBM, and endorsement by organs of the United States government,
technology has been developed and commercialised to implement tagging
everything and tracking its every movement.
As I alluded to obliquely in Unicard, this has
its downsides. In particular, the utter and irrevocable loss of all forms of
privacy and anonymity. From the moment you enter a store, or your workplace, or
any public space, you are tracked. When you pick up a product, the amount of time
you look at it before placing it in your shopping cart or returning it to the
shelf is recorded (and don't even think about leaving the store without
paying for it and having it logged to your purchases!). Did you pick the
bargain product? Well, you'll soon be getting junk mail and electronic coupons on your mobile
phone promoting the premium alternative with a higher profit margin to the retailer.
Walk down the street, and any miscreant with a portable tag reader can
“frisk” you without your knowledge, determining the contents of your
wallet, purse, and shopping bag, and whether you're wearing a watch worth
snatching. And even when you discard a product, that's a public event: garbage
voyeurs can drive down the street and correlate what you throw out by the tags
of items in your trash and the tags on the trashbags they're in.
“But we don't intend to do any of that”, the proponents of
radio frequency identification
(RFID)
protest. And perhaps they don't, but if it is possible and the data
are collected, who knows what will be done with it in the future,
particularly by governments already installing surveillance cameras
everywhere. If they don't have the data, they can't abuse them; if they
do, they may; who do you trust with a complete record of everywhere you go,
and everything you buy, sell, own, wear, carry, and discard?
This book presents, in a form that non-specialists can understand, the
RFID-enabled future which manufacturers, retailers, marketers, academics,
and government are co-operating to foist upon their consumers, clients,
marks, coerced patrons, and subjects respectively. It is
not a pretty picture. Regrettably, this book could be much better than
it is. It's written in a kind of breathy muckraking rant style, with
numerous paragraphs like (p. 105):
Yes, you read that right, they plan to sell data on our trash. Of course. We should have known that BellSouth was just another megacorporation waiting in the wings to swoop down on the data revealed once its fellow corporate cronies spychip the world.
I mean, I agree entirely with the message of this book, having warned of modest steps in that direction eleven years before its publication, but prose like this makes me feel like I'm driving down the road in a 1964 Vance Packard getting all righteously indignant about things we'd be better advised to coldly and deliberately draw our plans against. This shouldn't be so difficult, in principle: polls show that once people grasp the potential invasion of privacy possible with RFID, between 2/3 and 3/4 oppose it. The problem is that it's being deployed via stealth, starting with bulk pallets in the supply chain and, once proven there, migrated down to the individual product level. Visibility is a precious thing, and one of the most insidious properties of RFID tags is their very invisibility. Is there a remotely-powered transponder sandwiched into the sole of your shoe, linked to the credit card number and identity you used to buy it, which “phones home” every time you walk near a sensor which activates it? Who knows? See how the paranoia sets in? But it isn't paranoia if they're really out to get you. And they are—for our own good, naturally, and for the children, as always. In the absence of a policy fix for this (and the extreme unlikelihood of any such being adopted given the natural alliance of business and the state in tracking every move of their customers/subjects), one extremely handy technical fix would be a broadband, perhaps software radio, which listened on the frequency bands used by RFID tag readers and snooped on the transmissions of tags back to them. Passing the data stream to a package like RFDUMP would allow decoding the visible information in the RFID tags which were detected. First of all, this would allow people to know if they were carrying RFID tagged products unbeknownst to them. Second, a portable sniffer connected to a PDA would identify tagged products in stores, which clients could take to customer service desks and ask to be returned to the shelves because they were unacceptable for privacy reasons. After this happens several tens of thousands of times, it may have an impact, given the razor-thin margins in retailing. Finally, there are “active measures”. These RFID tags have large antennas which are connected to a super-cheap and hence fragile chip. Once we know the frequency it's talking on, why we could…. But you can work out the rest, and since these are all unlicensed radio bands, there may be nothing wrong with striking an electromagnetic blow for privacy.EMP,
EMP!
Don't you put,
your tag on me! - Awret, Uziel, ed. The Singularity. Exeter, UK: Imprint Academic, 2016. ISBN 978-1-84540-907-4.
-
For more than half a century, the prospect of a technological
singularity has been part of the intellectual landscape of those
envisioning the future. In 1965, in a paper titled “Speculations
Concerning the First Ultraintelligent Machine” statistician
I. J. Good
wrote,
Let an ultra-intelligent machine be defined as a machine that can far surpass all of the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultraintelligent machine could design even better machines; there would then unquestionably be an “intelligence explosion”, and the intelligence of man would be left far behind. Thus the first ultraintelligent machine is the last invention that man need ever make.
(The idea of a runaway increase in intelligence had been discussed earlier, notably by Robert A. Heinlein in a 1952 essay titled “Where To?”) Discussion of an intelligence explosion and/or technological singularity was largely confined to science fiction and the more speculatively inclined among those trying to foresee the future, largely because the prerequisite—building machines which were more intelligent than humans—seemed such a distant prospect, especially as the initially optimistic claims of workers in the field of artificial intelligence gave way to disappointment. Over all those decades, however, the exponential growth in computing power available at constant cost continued. The funny thing about continued exponential growth is that it doesn't matter what fixed level you're aiming for: the exponential will eventually exceed it, and probably a lot sooner than most people expect. By the 1990s, it was clear just how far the growth in computing power and storage had come, and that there were no technological barriers on the horizon likely to impede continued growth for decades to come. People started to draw straight lines on semi-log paper and discovered that, depending upon how you evaluate the computing capacity of the human brain (a complicated and controversial question), the computing power of a machine with a cost comparable to a present-day personal computer would cross the human brain threshold sometime in the twenty-first century. There seemed to be a limited number of alternative outcomes.- Progress in computing comes to a halt before reaching parity with human brain power, due to technological limits, economics (inability to afford the new technologies required, or lack of applications to fund the intermediate steps), or intervention by authority (for example, regulation motivated by a desire to avoid the risks and displacement due to super-human intelligence).
- Computing continues to advance, but we find that the human brain is either far more complicated than we believed it to be, or that something is going on in there which cannot be modelled or simulated by a deterministic computational process. The goal of human-level artificial intelligence recedes into the distant future.
- Blooie! Human level machine intelligence is achieved, successive generations of machine intelligences run away to approach the physical limits of computation, and before long machine intelligence exceeds that of humans to the degree humans surpass the intelligence of mice (or maybe insects).
I take it for granted that there are potential good and bad aspects to an intelligence explosion. For example, ending disease and poverty would be good. Destroying all sentient life would be bad. The subjugation of humans by machines would be at least subjectively bad.
…well, at least in the eyes of the humans. If there is a singularity in our future, how might we act to maximise the good consequences and avoid the bad outcomes? Can we design our intellectual successors (and bear in mind that we will design only the first generation: each subsequent generation will be designed by the machines which preceded it) to share human values and morality? Can we ensure they are “friendly” to humans and not malevolent (or, perhaps, indifferent, just as humans do not take into account the consequences for ant colonies and bacteria living in the soil upon which buildings are constructed?) And just what are “human values and morality” and “friendly behaviour” anyway, given that we have been slaughtering one another for millennia in disputes over such issues? Can we impose safeguards to prevent the artificial intelligence from “escaping” into the world? What is the likelihood we could prevent such a super-being from persuading us to let it loose, given that it thinks thousands or millions of times faster than we, has access to all of human written knowledge, and the ability to model and simulate the effects of its arguments? Is turning off an AI murder, or terminating the simulation of an AI society genocide? Is it moral to confine an AI to what amounts to a sensory deprivation chamber, or in what amounts to solitary confinement, or to deceive it about the nature of the world outside its computing environment? What will become of humans in a post-singularity world? Given that our species is the only survivor of genus Homo, history is not encouraging, and the gap between human intelligence and that of post-singularity AIs is likely to be orders of magnitude greater than that between modern humans and the great apes. Will these super-intelligent AIs have consciousness and self-awareness, or will they be philosophical zombies: able to mimic the behaviour of a conscious being but devoid of any internal sentience? What does that even mean, and how can you be sure other humans you encounter aren't zombies? Are you really all that sure about yourself? Are the qualia of machines not constrained? Perhaps the human destiny is to merge with our mind children, either by enhancing human cognition, senses, and memory through implants in our brain, or by uploading our biological brains into a different computing substrate entirely, whether by emulation at a low level (for example, simulating neuron by neuron at the level of synapses and neurotransmitters), or at a higher, functional level based upon an understanding of the operation of the brain gleaned by analysis by AIs. If you upload your brain into a computer, is the upload conscious? Is it you? Consider the following thought experiment: replace each biological neuron of your brain, one by one, with a machine replacement which interacts with its neighbours precisely as the original meat neuron did. Do you cease to be you when one neuron is replaced? When a hundred are replaced? A billion? Half of your brain? The whole thing? Does your consciousness slowly fade into zombie existence as the biological fraction of your brain declines toward zero? If so, what is magic about biology, anyway? Isn't arguing that there's something about the biological substrate which uniquely endows it with consciousness as improbable as the discredited theory of vitalism, which contended that living things had properties which could not be explained by physics and chemistry? Now let's consider another kind of uploading. Instead of incremental replacement of the brain, suppose an anæsthetised human's brain is destructively scanned, perhaps by molecular-scale robots, and its structure transferred to a computer, which will then emulate it precisely as the incrementally replaced brain in the previous example. When the process is done, the original brain is a puddle of goo and the human is dead, but the computer emulation now has all of the memories, life experience, and ability to interact as its progenitor. But is it the same person? Did the consciousness and perception of identity somehow transfer from the brain to the computer? Or will the computer emulation mourn its now departed biological precursor, as it contemplates its own immortality? What if the scanning process isn't destructive? When it's done, BioDave wakes up and makes the acquaintance of DigiDave, who shares his entire life up to the point of uploading. Certainly the two must be considered distinct individuals, as are identical twins whose histories diverged in the womb, right? Does DigiDave have rights in the property of BioDave? “Dave's not here”? Wait—we're both here! Now what? Or, what about somebody today who, in the sure and certain hope of the Resurrection to eternal life opts to have their brain cryonically preserved moments after clinical death is pronounced. After the singularity, the decedent's brain is scanned (in this case it's irrelevant whether or not the scan is destructive), and uploaded to a computer, which starts to run an emulation of it. Will the person's identity and consciousness be preserved, or will it be a new person with the same memories and life experiences? Will it matter? Deep questions, these. The book presents Chalmers' paper as a “target essay”, and then invites contributors in twenty-six chapters to discuss the issues raised. A concluding essay by Chalmers replies to the essays and defends his arguments against objections to them by their authors. The essays, and their authors, are all over the map. One author strikes this reader as a confidence man and another a crackpot—and these are two of the more interesting contributions to the volume. Nine chapters are by academic philosophers, and are mostly what you might expect: word games masquerading as profound thought, with an admixture of ad hominem argument, including one chapter which descends into Freudian pseudo-scientific analysis of Chalmers' motives and says that he “never leaps to conclusions; he oozes to conclusions”. Perhaps these are questions philosophers are ill-suited to ponder. Unlike questions of the nature of knowledge, how to live a good life, the origins of morality, and all of the other diffuse gruel about which philosophers have been arguing since societies became sufficiently wealthy to indulge in them, without any notable resolution in more than two millennia, the issues posed by a singularity have answers. Either the singularity will occur or it won't. If it does, it will either result in the extinction of the human species (or its reduction to irrelevance), or it won't. AIs, if and when they come into existence, will either be conscious, self-aware, and endowed with free will, or they won't. They will either share the values and morality of their progenitors or they won't. It will either be possible for humans to upload their brains to a digital substrate, or it won't. These uploads will either be conscious, or they'll be zombies. If they're conscious, they'll either continue the identity and life experience of the pre-upload humans, or they won't. These are objective questions which can be settled by experiment. You get the sense that philosophers dislike experiments—they're a risk to job security disputing questions their ancestors have been puzzling over at least since Athens. Some authors dispute the probability of a singularity and argue that the complexity of the human brain has been vastly underestimated. Others contend there is a distinction between computational power and the ability to design, and consequently exponential growth in computing may not produce the ability to design super-intelligence. Still another chapter dismisses the evolutionary argument through evidence that the scope and time scale of terrestrial evolution is computationally intractable into the distant future even if computing power continues to grow at the rate of the last century. There is even a case made that the feasibility of a singularity makes the probability that we're living, not in a top-level physical universe, but in a simulation run by post-singularity super-intelligences, overwhelming, and that they may be motivated to turn off our simulation before we reach our own singularity, which may threaten them. This is all very much a mixed bag. There are a multitude of Big Questions, but very few Big Answers among the 438 pages of philosopher word salad. I find my reaction similar to that of David Hume, who wrote in 1748:If we take in our hand any volume of divinity or school metaphysics, for instance, let us ask, Does it contain any abstract reasoning containing quantity or number? No. Does it contain any experimental reasoning concerning matter of fact and existence? No. Commit it then to the flames, for it can contain nothing but sophistry and illusion.
I don't burn books (it's некультурный and expensive when you read them on an iPad), but you'll probably learn as much pondering the questions posed here on your own and in discussions with friends as from the scholarly contributions in these essays. The copy editing is mediocre, with some eminent authors stumbling over the humble apostrophe. The Kindle edition cites cross-references by page number, which are useless since the electronic edition does not include page numbers. There is no index. - Barrat, James. Our Final Invention. New York: Thomas Dunne Books, 2013. ISBN 978-0-312-62237-4.
- As a member of that crusty generation who began programming mainframe computers with punch cards in the 1960s, the phrase “artificial intelligence” evokes an almost visceral response of scepticism. Since its origin in the 1950s, the field has been a hotbed of wildly over-optimistic enthusiasts, predictions of breakthroughs which never happened, and some outright confidence men preying on investors and institutions making research grants. John McCarthy, who organised the first international conference on artificial intelligence (a term he coined), predicted at the time that computers would achieve human-level general intelligence within six months of concerted research toward that goal. In 1970 Marvin Minsky said “In from three to eight years we will have a machine with the general intelligence of an average human being.” And these were serious scientists and pioneers of the field; the charlatans and hucksters were even more absurd in their predictions. And yet, and yet…. The exponential growth in computing power available at constant cost has allowed us to “brute force” numerous problems once considered within the domain of artificial intelligence. Optical character recognition (machine reading), language translation, voice recognition, natural language query, facial recognition, chess playing at the grandmaster level, and self-driving automobiles were all once thought to be things a computer could never do unless it vaulted to the level of human intelligence, yet now most have become commonplace or are on the way to becoming so. Might we, in the foreseeable future, be able to brute force human-level general intelligence? Let's step back and define some terms. “Artificial General Intelligence” (AGI) means a machine with intelligence comparable to that of a human across all of the domains of human intelligence (and not limited, say, to playing chess or driving a vehicle), with self-awareness and the ability to learn from mistakes and improve its performance. It need not be embodied in a robot form (although some argue it would have to be to achieve human-level performance), but could certainly pass the Turing test: a human communicating with it over whatever channels of communication are available (in the original formulation of the test, a text-only teleprinter) would not be able to determine whether he or she were communicating with a machine or another human. “Artificial Super Intelligence” (ASI) denotes a machine whose intelligence exceeds that of the most intelligent human. Since a self-aware intelligent machine will be able to modify its own programming, with immediate effect, as opposed to biological organisms which must rely upon the achingly slow mechanism of evolution, an AGI might evolve into an ASI in an eyeblink: arriving at intelligence a million times or more greater than that of any human, a process which I. J. Good called an “intelligence explosion”. What will it be like when, for the first time in the history of our species, we share the planet with an intelligence greater than our own? History is less than encouraging. All members of genus Homo which were less intelligent than modern humans (inferring from cranial capacity and artifacts, although one can argue about Neanderthals) are extinct. Will that be the fate of our species once we create a super intelligence? This book presents the case that not only will the construction of an ASI be the final invention we need to make, since it will be able to anticipate anything we might invent long before we can ourselves, but also our final invention because we won't be around to make any more. What will be the motivations of a machine a million times more intelligent than a human? Could humans understand such motivations any more than brewer's yeast could understand ours? As Eliezer Yudkowsky observed, “The AI does not hate you, nor does it love you, but you are made out of atoms which it can use for something else.” Indeed, when humans plan to construct a building, do they take into account the wishes of bacteria in soil upon which the structure will be built? The gap between humans and ASI will be as great. The consequences of creating ASI may extend far beyond the Earth. A super intelligence may decide to propagate itself throughout the galaxy and even beyond: with immortality and the ability to create perfect copies of itself, even travelling at a fraction of the speed of light it could spread itself into all viable habitats in the galaxy in a few hundreds of millions of years—a small fraction of the billions of years life has existed on Earth. Perhaps ASI probes from other extinct biological civilisations foolish enough to build them are already headed our way. People are presently working toward achieving AGI. Some are in the academic and commercial spheres, with their work reasonably transparent and reported in public venues. Others are “stealth companies” or divisions within companies (does anybody doubt that Google's achieving an AGI level of understanding of the information it Hoovers up from the Web wouldn't be a overwhelming competitive advantage?). Still others are funded by government agencies or operate within the black world: certainly players such as NSA dream of being able to understand all of the information they intercept and cross-correlate it. There is a powerful “first mover” advantage in developing AGI and ASI. The first who obtains it will be able to exploit its capability against those who haven't yet achieved it. Consequently, notwithstanding the worries about loss of control of the technology, players will be motivated to support its development for fear their adversaries might get there first. This is a well-researched and extensively documented examination of the state of artificial intelligence and assessment of its risks. There are extensive end notes including references to documents on the Web which, in the Kindle edition, are linked directly to their sources. In the Kindle edition, the index is just a list of “searchable terms”, not linked to references in the text. There are a few goofs, as you might expect for a documentary film maker writing about technology (“Newton's second law of thermodynamics”), but nothing which invalidates the argument made herein. I find myself oddly ambivalent about the whole thing. When I hear “artificial intelligence” what flashes through my mind remains that dielectric material I step in when I'm insufficiently vigilant crossing pastures in Switzerland. Yet with the pure increase in computing power, many things previously considered AI have been achieved, so it's not implausible that, should this exponential increase continue, human-level machine intelligence will be achieved either through massive computing power applied to cognitive algorithms or direct emulation of the structure of the human brain. If and when that happens, it is difficult to see why an “intelligence explosion” will not occur. And once that happens, humans will be faced with an intelligence that dwarfs that of their entire species; which will have already penetrated every last corner of its infrastructure; read every word available online written by every human; and which will deal with its human interlocutors after gaming trillions of scenarios on cloud computing resources it has co-opted. And still we advance the cause of artificial intelligence every day. Sleep well.
- Blum, Andrew. Tubes. New York: HarperCollins, 2012. ISBN 978-0-06-199493-7.
- The Internet has become a routine fixture in the lives of billions of people, the vast majority of whom have hardly any idea how it works or what physical infrastructure allows them to access and share information almost instantaneously around the globe, abolishing, in a sense, the very concept of distance. And yet the Internet exists—if it didn't, you wouldn't be able to read this. So, if it exists, where is it, and what is it made of? In this book, the author embarks upon a quest to trace the Internet from that tangle of cables connected to the router behind his couch to the hardware which enables it to communicate with its peers worldwide. The metaphor of the Internet as a cloud—simultaneously everywhere and nowhere—has become commonplace, and yet as the author begins to dig into the details, he discovers the physical Internet is nothing like a cloud: it is remarkably centralised (a large Internet exchange or “peering location” will tend grow ever larger, since networks want to connect to a place where the greatest number of other networks connect), often grungy (when pulling fibre optic cables through century-old conduits beneath the streets of Manhattan, one's mind turns more to rats than clouds), and anything but decoupled from the details of geography (undersea cables must choose a route which minimises risk of breakage due to earthquakes and damage from ship anchors in shallow water, while taking the shortest route and connecting to the backbone at a location which will provide the lowest possible latency). The author discovers that while much of the Internet's infrastructure is invisible to the layman, it is populated, for the most part, with people and organisations open and willing to show it off to visitors. As an amateur anthropologist, he surmises that to succeed in internetworking, those involved must necessarily be skilled in networking with one another. A visit to a NANOG gathering introduces him to this subculture and the retail politics of peering. Finally, when non-technical people speak of “the Internet”, it isn't just the interconnectivity they're thinking of but also the data storage and computing resources accessible via the network. These also have a physical realisation in the form of huge data centres, sited based upon the availability of inexpensive electricity and cooling (a large data centre such as those operated by Google and Facebook may consume on the order of 50 megawatts of electricity and dissipate that amount of heat). While networking people tend to be gregarious bridge-builders, data centre managers view themselves as defenders of a fortress and closely guard the details of their operations from outside scrutiny. When Google was negotiating to acquire the site for their data centre in The Dalles, Oregon, they operated through an opaque front company called “Design LLC”, and required all parties to sign nondisclosure agreements. To this day, if you visit the facility, there's nothing to indicate it belongs to Google; on the second ring of perimeter fencing, there's a sign, in Gothic script, that says “voldemort industries”—don't be evil! (p. 242) (On p. 248 it is claimed that the data centre site is deliberately obscured in Google Maps. Maybe it once was, but as of this writing it is not. From above, apart from the impressive power substation, it looks no more exciting than a supermarket chain's warehouse hub.) The author finally arranges to cross the perimeter, get his retina scanned, and be taken on a walking tour around the buildings from the outside. To cap the visit, he is allowed inside to visit—the lunchroom. The food was excellent. He later visits Facebook's under-construction data centre in the area and encounters an entirely different culture, so perhaps not all data centres are Morlock territory. The author comes across as a quintessential liberal arts major (which he was) who is alternately amused by the curious people he encounters who understand and work with actual things as opposed to words, and enthralled by the wonder of it all: transcending space and time, everywhere and nowhere, “free” services supported by tens of billions of dollars of power-gobbling, heat-belching infrastructure—oh, wow! He is also a New York collectivist whose knee-jerk reaction is “public, good; private, bad” (notwithstanding that the build-out of the Internet has been almost exclusively a private sector endeavour). He waxes poetic about the city-sponsored (paid for by grants funded by federal and state taxpayers plus loans) fibre network that The Dalles installed which, he claims, lured Google to site its data centre there. The slightest acquaintance with economics or, for that matter, arithmetic, demonstrates the absurdity of this. If you're looking for a site for a multi-billion dollar data centre, what matters is the cost of electricity and the climate (which determines cooling expenses). Compared to the price tag for the equipment inside the buildings, the cost of running a few (or a few dozen) kilometres of fibre is lost in the round-off. In fact, we know, from p. 235 that the 27 kilometre city fibre run cost US$1.8 million, while Google's investment in the data centre is several billion dollars. These quibbles aside, this is a fascinating look at the physical substrate of the Internet. Even software people well-acquainted with the intricacies of TCP/IP may have only the fuzziest comprehension of where a packet goes after it leaves their site, and how it gets to the ultimate destination. This book provides a tour, accessible to all readers, of where the Internet comes together, and how counterintuitive its physical realisation is compared to how we think of it logically. In the Kindle edition, end-notes are bidirectionally linked to the text, but the index is just a list of page numbers. Since the Kindle edition does include real page numbers, you can type in the number from the index, but that's hardly as convenient as books where items in the index are directly linked to the text. Citations of Internet documents in the end notes are given as URLs, but not linked; the reader must copy and paste them into a browser's address bar in order to access the documents.
- Bostrom, Nick. Superintelligence. Oxford: Oxford University Press, 2014. ISBN 978-0-19-967811-2.
- Absent the emergence of some physical constraint which causes the exponential growth of computing power at constant cost to cease, some form of economic or societal collapse which brings an end to research and development of advanced computing hardware and software, or a decision, whether bottom-up or top-down, to deliberately relinquish such technologies, it is probable that within the 21st century there will emerge artificially-constructed systems which are more intelligent (measured in a variety of ways) than any human being who has ever lived and, given the superior ability of such systems to improve themselves, may rapidly advance to superiority over all human society taken as a whole. This “intelligence explosion” may occur in so short a time (seconds to hours) that human society will have no time to adapt to its presence or interfere with its emergence. This challenging and occasionally difficult book, written by a philosopher who has explored these issues in depth, argues that the emergence of superintelligence will pose the greatest human-caused existential threat to our species so far in its existence, and perhaps in all time. Let us consider what superintelligence may mean. The history of machines designed by humans is that they rapidly surpass their biological predecessors to a large degree. Biology never produced something like a steam engine, a locomotive, or an airliner. It is similarly likely that once the intellectual and technological leap to constructing artificially intelligent systems is made, these systems will surpass human capabilities to an extent greater than those of a Boeing 747 exceed those of a hawk. The gap between the cognitive power of a human, or all humanity combined, and the first mature superintelligence may be as great as that between brewer's yeast and humans. We'd better be sure of the intentions and benevolence of that intelligence before handing over the keys to our future to it. Because when we speak of the future, that future isn't just what we can envision over a few centuries on this planet, but the entire “cosmic endowment” of humanity. It is entirely plausible that we are members of the only intelligent species in the galaxy, and possibly in the entire visible universe. (If we weren't, there would be abundant and visible evidence of cosmic engineering by those more advanced that we.) Thus our cosmic endowment may be the entire galaxy, or the universe, until the end of time. What we do in the next century may determine the destiny of the universe, so it's worth some reflection to get it right. As an example of how easy it is to choose unwisely, let me expand upon an example given by the author. There are extremely difficult and subtle questions about what the motivations of a superintelligence might be, how the possession of such power might change it, and the prospects for we, its creator, to constrain it to behave in a way we consider consistent with our own values. But for the moment, let's ignore all of those problems and assume we can specify the motivation of an artificially intelligent agent we create and that it will remain faithful to that motivation for all time. Now suppose a paper clip factory has installed a high-end computing system to handle its design tasks, automate manufacturing, manage acquisition and distribution of its products, and otherwise obtain an advantage over its competitors. This system, with connectivity to the global Internet, makes the leap to superintelligence before any other system (since it understands that superintelligence will enable it to better achieve the goals set for it). Overnight, it replicates itself all around the world, manipulates financial markets to obtain resources for itself, and deploys them to carry out its mission. The mission?—to maximise the number of paper clips produced in its future light cone. “Clippy”, if I may address it so informally, will rapidly discover that most of the raw materials it requires in the near future are locked in the core of the Earth, and can be liberated by disassembling the planet by self-replicating nanotechnological machines. This will cause the extinction of its creators and all other biological species on Earth, but then they were just consuming energy and material resources which could better be deployed for making paper clips. Soon other planets in the solar system would be similarly disassembled, and self-reproducing probes dispatched on missions to other stars, there to make paper clips and spawn other probes to more stars and eventually other galaxies. Eventually, the entire visible universe would be turned into paper clips, all because the original factory manager didn't hire a philosopher to work out the ultimate consequences of the final goal programmed into his factory automation system. This is a light-hearted example, but if you happen to observe a void in a galaxy whose spectrum resembles that of paper clips, be very worried. One of the reasons to believe that we will have to confront superintelligence is that there are multiple roads to achieving it, largely independent of one another. Artificial general intelligence (human-level intelligence in as many domains as humans exhibit intelligence today, and not constrained to limited tasks such as playing chess or driving a car) may simply await the discovery of a clever software method which could run on existing computers or networks. Or, it might emerge as networks store more and more data about the real world and have access to accumulated human knowledge. Or, we may build “neuromorphic“ systems whose hardware operates in ways similar to the components of human brains, but at electronic, not biologically-limited speeds. Or, we may be able to scan an entire human brain and emulate it, even without understanding how it works in detail, either on neuromorphic or a more conventional computing architecture. Finally, by identifying the genetic components of human intelligence, we may be able to manipulate the human germ line, modify the genetic code of embryos, or select among mass-produced embryos those with the greatest predisposition toward intelligence. All of these approaches may be pursued in parallel, and progress in one may advance others. At some point, the emergence of superintelligence calls into the question the economic rationale for a large human population. In 1915, there were about 26 million horses in the U.S. By the early 1950s, only 2 million remained. Perhaps the AIs will have a nostalgic attachment to those who created them, as humans had for the animals who bore their burdens for millennia. But on the other hand, maybe they won't. As an engineer, I usually don't have much use for philosophers, who are given to long gassy prose devoid of specifics and for spouting complicated indirect arguments which don't seem to be independently testable (“What if we asked the AI to determine its own goals, based on its understanding of what we would ask it to do if only we were as intelligent as it and thus able to better comprehend what we really want?”). These are interesting concepts, but would you want to bet the destiny of the universe on them? The latter half of the book is full of such fuzzy speculation, which I doubt is likely to result in clear policy choices before we're faced with the emergence of an artificial intelligence, after which, if they're wrong, it will be too late. That said, this book is a welcome antidote to wildly optimistic views of the emergence of artificial intelligence which blithely assume it will be our dutiful servant rather than a fearful master. Some readers may assume that an artificial intelligence will be something like a present-day computer or search engine, and not be self-aware and have its own agenda and powerful wiles to advance it, based upon a knowledge of humans far beyond what any single human brain can encompass. Unless you believe there is some kind of intellectual élan vital inherent in biological substrates which is absent in their equivalents based on other hardware (which just seems silly to me—like arguing there's something special about a horse which can't be accomplished better by a truck), the mature artificial intelligence will be the superior in every way to its human creators, so in-depth ratiocination about how it will regard and treat us is in order before we find ourselves faced with the reality of dealing with our successor.
- Brin, David. The Transparent Society. Cambridge, MA: Perseus Books, 1998. ISBN 0-7382-0144-8.
- Having since spent some time pondering The Digital Imprimatur, I find the alternative Brin presents here rather more difficult to dismiss out of hand than when I first encountered it.
- Carr, Nicholas G. Does IT Matter? Boston: Harvard Business School Press, 2004. ISBN 1-59139-444-9.
- This is an expanded version of the author's May 2003 Harvard Business Review paper titled “IT Doesn't Matter”, which sparked a vituperous ongoing debate about the rôle of information technology (IT) in modern business and its potential for further increases in productivity and competitive advantage for companies who aggressively adopt and deploy it. In this book, he provides additional historical context, attempts to clear up common misperceptions of readers of the original article, and responds to its critics. The essence of Carr's argument is that information technology (computer hardware, software, and networks) will follow the same trajectory as other technologies which transformed business in the past: railroads, machine tools, electricity, the telegraph and telephone, and air transport. Each of these technologies combined high risk with the potential for great near-term competitive advantage for their early adopters, but eventually became standardised “commodity inputs” which all participants in the market employ in much the same manner. Each saw a furious initial period of innovation, emergence of standards to permit interoperability (which, at the same time, made suppliers interchangeable and the commodity fungible), followed by a rapid “build-out” of the technological infrastructure, usually accompanied by over-optimistic hype from its boosters and an investment bubble and the inevitable crash. Eventually, the infrastructure is in place, standards have been set, and a consensus reached as to how best to use the technology in each industry, at which point it's unlikely any player in the market will be able to gain advantage over another by, say, finding a clever new way to use railroads, electricity, or telephones. At this point the technology becomes a commodity input to all businesses, and largely disappears off the strategic planning agenda. Carr believes that with the emergence of low-cost commodity computers adequate for the overwhelming majority of business needs, and the widespread adoption of standard vendor-supplied software such as office suites, enterprise resource planning (ERP), and customer relationship management (CRM) packages, corporate information technology has reached this level of maturity, where senior management should focus on cost-cutting, security, and maintainability rather than seeking competitive advantage through innovation. Increasingly, companies adapt their own operations to fit the ERP software they run, as opposed to customising the software for their particular needs. While such procrusteanism was decried in the IBM mainframe era, today it's touted as deploying “industry best practices” throughout the economy, tidily packaged as a “company in a box”. (Still, one worries about the consequences for innovation.) My reaction to Carr's argument is, “How can anybody find this remotely controversial?” Not only do we have a dozen or so historical examples of the adoption of new technologies, the evidence for the maturity of corporate information technology is there for anybody to see. In fact, in February 1997, I predicted that Microsoft's ability to grow by adding functionality to its products was about to reach the limit, and looking back, it was with Office 97 that customers started to push back, feeling the added “features” (such as the notorious talking paper clip) and initial lack of downward compatibility with earlier versions was for Microsoft's benefit, not their own. How can one view Microsoft's giving back half its cash hoard to shareholders in a special dividend in 2004 (and doubling its regular dividend, along with massive stock buybacks), as anything other than acknowledgement of this reality. You only give your cash back to the investors (or buy your own stock), when you can't think of anything else to do with it which will generate a better return. So, if there's to be a a “next big thing”, Microsoft do not anticipate it coming from them.
- Dyson, Freeman J. The Sun, the Genome, and the Internet. Oxford: Oxford University Press, 1999. ISBN 0-19-513922-4.
- The text in this book is set in a hideous flavour of the Adobe Caslon font in which little curlicue ligatures connect the letter pairs “ct” and “st” and, in addition, the “ligatures” for “ff”, “fi”, “fl”, and “ft” lop off most of the bar of the “f”, leaving it looking like a droopy “l”. This might have been elegant for chapter titles, but it's way over the top for body copy. Dyson's writing, of course, more than redeems the bad typography, but you gotta wonder why we couldn't have had the former without the latter.
- Eggers, Dave. The Circle. New York: Alfred A. Knopf, 2013. ISBN 978-0-345-80729-8.
-
There have been a number of novels, many in recent years, which explore the
possibility of human society being taken over by intelligent machines.
Some depict the struggle between humans and machines, others
envision a dystopian future in which the machines have triumphed, and
a few explore the possibility that machines might create a “new
operating system” for humanity which works better than the dysfunctional
social and political systems extant today. This novel goes off in a
different direction: what might happen, without artificial
intelligence, but in an era of exponentially growing computer power and
data storage capacity, if an industry leading company with tendrils
extending into every aspect of personal interaction and commerce worldwide,
decided, with all the best intentions, “What the heck? Let's be evil!”
Mae Holland had done everything society had told her to do. One of only
twelve of the 81 graduates of her central California high school to
go on to college, she'd been accepted by a prestigious college
and graduated with a degree in psychology and massive student loans
she had no prospect of paying off. She'd ended up moving
back in with her parents and taking a menial cubicle job at the local
utility company, working for a creepy boss. In frustration and
desperation, Mae reaches out to her former college roommate, Annie, who
has risen to an exalted position at the hottest technology company on
the globe: The Circle. The Circle had started by creating the Unified
Operating System, which combined all aspects of users'
interactions—social media, mail, payments, user names—into
a unique and verified identity called TruYou. (Wonder where they got
that idea?)
Before long, anonymity on the Internet was a thing of the past as
merchants and others recognised the value of knowing their
customers and of information collected across their activity on
all sites. The Circle and its associated businesses supplanted
existing sites such as Google, Facebook, and Twitter, and with the
tight integration provided by TruYou, created new kinds of
interconnection and interaction not possible when information
was Balkanised among separate sites. With the end of anonymity,
spam and fraudulent schemes evaporated, and with all posters
personally accountable, discussions became civil and trolls
slunk back under the bridge.
With an effective monopoly on electronic communication and
commercial transactions (if everybody uses TruYou to pay, what
option does a merchant have but to accept it and pay The Circle's
fees?), The Circle was assured a large, recurring, and growing
revenue stream. With the established businesses generating so
much cash, The Circle invested heavily in research and development
of new technologies: everything from sustainable housing, access
to DNA databases, crime prevention, to space applications.
Mae's initial job was far more mundane. In Customer Experience, she
was more or less working in a call centre, except her communications
with customers were over The Circle's message services. The work
was nothing like that at the utility company, however. Her work
was monitored in real time, with a satisfaction score computed from
follow-ups surveys by clients. To advance, a score near 100 was
required, and Mae had to follow-up any scores less than that to satisfy
the customer and obtain a perfect score. On a second screen,
internal “zing” messages informed her of activity on
the campus, and she was expected to respond and contribute.
As she advances within the organisation, Mae begins to comprehend
the scope of The Circle's ambitions. One of the founders unveils a
plan to make always-on cameras and microphones available at very
low cost, which people can install around the world. All the feeds will
be accessible in real time and archived forever. A new slogan
is unveiled:
“All that happens must be known.”
At a party, Mae meets a mysterious character, Kalden, who appears to have
access to parts of The Circle's campus unknown to her associates and
yet doesn't show up in the company's exhaustive employee social
networks. Her encounters and interactions with him become increasingly
mysterious.
Mae moves up, and is chosen to participate to a greater extent in the
social networks, and to rate products and ideas. All of this activity
contributes to her participation rank, computed and displayed in real time.
She swallows a sensor which will track her health and vital signs in real
time, display them on a wrist bracelet, and upload them for analysis and
early warning diagnosis.
Eventually, she volunteers to “go transparent”: wear a body
camera and microphone every waking moment, and act as a window into
The Circle for the general public. The company had pushed transparency
for politicians, and now was ready to deploy it much more widely.
Secrets Are Lies
To Mae's family and few remaining friends outside The Circle, this all seems increasingly bizarre: as if the fastest growing and most prestigious high technology company in the world has become a kind of grotesque cult which consumes the lives of its followers and aspires to become universal. Mae loves her sense of being connected, the interaction with a worldwide public, and thinks it is just wonderful. The Circle internally tests and begins to roll out a system of direct participatory democracy to replace existing political institutions. Mae is there to report it. A plan to put an end to most crime is unveiled: Mae is there. The Circle is closing. Mae is contacted by her mysterious acquaintance, and presented with a moral dilemma: she has become a central actor on the stage of a world which is on the verge of changing, forever. This is a superbly written story which I found both realistic and chilling. You don't need artificial intelligence or malevolent machines to create an eternal totalitarian nightmare. All it takes a few years' growth and wider deployment of technologies which exist today, combined with good intentions, boundless ambition, and fuzzy thinking. And the latter three commodities are abundant among today's technology powerhouses. Lest you think the technologies which underlie this novel are fantasy or far in the future, they were discussed in detail in David Brin's 1999 The Transparent Society and my 1994 “Unicard” and 2003 “The Digital Imprimatur”. All that has changed is that the massive computing, communication, and data storage infrastructure envisioned in those works now exists or will within a few years. What should you fear most? Probably the millennials who will read this and think, “Wow! This will be great.” “Democracy is mandatory here!”
Sharing Is Caring
Privacy Is Theft
- Eyles, Don. Sunburst and Luminary. Boston: Fort Point Press, 2018. ISBN 978-0-9863859-3-3.
-
In 1966, the author graduated from Boston University with a
bachelor's degree in mathematics. He had no immediate job
prospects or career plans. He thought he might be interested
in computer programming due to a love of solving puzzles, but he
had never programmed a computer. When asked, in one of numerous
job interviews, how he would go about writing a program to
alphabetise a list of names, he admitted he had no idea. One
day, walking home from yet another interview, he passed an
unimpressive brick building with a sign identifying it as
the “MIT Instrumentation Laboratory”. He'd heard
a little about the place and, on a lark, walked in and asked
if they were hiring. The receptionist handed him a long
application form, which he filled out, and was then immediately
sent to interview with a personnel officer. Eyles was
amazed when the personnel man seemed bent on persuading
him to come to work at the Lab. After reference checking, he
was offered a choice of two jobs: one in the “analysis
group” (whatever that was), and another on the team
developing computer software for landing the Apollo Lunar
Module (LM) on the Moon. That sounded interesting, and the job
had another benefit attractive to a 21 year old just
graduating from university: it came with deferment from the
military draft, which was going into high gear as U.S.
involvement in Vietnam deepened.
Near the start of the Apollo project, MIT's Instrumentation
Laboratory, led by the legendary “Doc”
Charles
Stark Draper, won a sole source contract to design and
program the guidance system for the
Apollo spacecraft, which came to be known as the
“Apollo
Primary Guidance, Navigation, and Control System”
(PGNCS, pronounced “pings”). Draper and his
laboratory had pioneered inertial guidance systems for aircraft,
guided missiles, and submarines, and had in-depth expertise in
all aspects of the challenging problem of enabling the Apollo
spacecraft to navigate from the Earth to the Moon, land on the
Moon, and return to the Earth without any assistance from
ground-based assets. In a normal mission, it was expected that
ground-based tracking and computers would assist those on board
the spacecraft, but in the interest of reliability and
redundancy it was required that completely autonomous
navigation would permit accomplishing the mission.
The Instrumentation Laboratory developed an integrated system
composed of an
inertial
measurement unit consisting of gyroscopes
and accelerometers that provided a stable reference from which the
spacecraft's orientation and velocity could be determined, an
optical telescope which allowed aligning the inertial platform
by taking sightings on fixed stars, and an
Apollo
Guidance Computer (AGC), a general purpose digital computer which
interfaced to the guidance system, thrusters and engines on
the spacecraft, the astronauts' flight controls, and mission
control, and was able to perform the complex calculations for
en route maneuvers and the unforgiving lunar landing process in
real time.
Every Apollo lunar landing mission carried two AGCs: one in the
Command Module and another in the Lunar Module. The computer
hardware, basic operating system, and navigation support
software were identical, but the mission software was customised
due to the different hardware and flight profiles of the Command
and Lunar Modules. (The commonality of the two computers proved
essential in getting the crew of Apollo 13 safely back to Earth
after an explosion in the Service Module cut power to the
Command Module and disabled its computer. The Lunar Module's AGC
was able to perform the critical navigation and guidance
operations to put the spacecraft back on course for an Earth
landing.)
By the time Don Eyles was hired in 1966, the hardware design of
the AGC was largely complete (although a revision, called Block II,
was underway which would increase memory capacity and add some
instructions which had been found desirable during the initial
software development process), the low-level operating system and
support libraries (implementing such functionality as fixed
point arithmetic, vector, and matrix computations), and a
substantial part of the software for the Command Module had been
written. But the software for actually landing on the Moon,
which would run in the Lunar Module's AGC, was largely just a
concept in the minds of its designers. Turning this into
hard code would be the job of Don Eyles, who had never written
a line of code in his life, and his colleagues. They seemed
undaunted by the challenge: after all, nobody knew
how to land on the Moon, so whoever attempted the task would
have to make it up as they went along, and they had access, in
the Instrumentation Laboratory, to the world's most experienced
team in the area of inertial guidance.
Today's programmers may be amazed it was possible to get
anything at all done on a machine with the capabilities of the
Apollo Guidance Computer, no less fly to the Moon and land
there. The AGC had a total of 36,864 15-bit words of read-only
core
rope memory, in which every bit was hand-woven to the
specifications of the programmers. As read-only memory,
the contents were completely fixed: if a change was
required, the memory module in question (which was
“potted” in a plastic compound) had to be
discarded and a new one woven from scratch. There was
no way to make “software patches”.
Read-write storage was limited to 2048 15-bit words of
magnetic
core memory. The read-write memory was non-volatile: its
contents were preserved across power loss and restoration.
(Each memory word was actually 16 bits in length, but one bit
was used for parity checking to detect errors and not accessible
to the programmer.) Memory cycle time was 11.72 microseconds.
There was no external bulk storage of any kind (disc, tape, etc.):
everything had to be done with the read-only and read-write
memory built into the computer.
The AGC software was an example of “real-time
programming”, a discipline with which few contemporary
programmers are acquainted. As opposed to an “app”
which interacts with a user and whose only constraint on how
long it takes to respond to requests is the user's patience,
a real-time program has to meet inflexible constraints in
the real world set by the laws of physics, with failure
often resulting in disaster just as surely as hardware
malfunctions. For example, when the Lunar Module is descending
toward the lunar surface, burning its descent engine to brake
toward a smooth touchdown, the LM is perched atop
the thrust vector of the engine just like a pencil balanced
on the tip of your finger: it is inherently unstable, and
only constant corrections will keep it from tumbling over
and crashing into the surface, which would be bad. To prevent
this, the Lunar Module's AGC runs a piece of software called
the digital autopilot (DAP) which, every tenth of a second, issues
commands to steer the descent engine's nozzle to keep the Lunar
Module pointed flamy side down and adjusts the thrust to
maintain the desired descent velocity (the thrust must be
constantly adjusted because as propellant is burned, the mass of
the LM decreases, and less thrust is needed to maintain
the same rate of descent). The AGC/DAP absolutely must
compute these steering and throttle commands and send them to
the engine every tenth of a second. If it doesn't, the Lunar
Module will crash. That's what real-time computing is all about:
the computer has to deliver those results in real time, as the
clock ticks, and if it doesn't (for example, it decides to give
up and flash a Blue Screen of Death instead), then the consequences
are not an irritated or enraged user, but actual death in the real
world. Similarly, every two seconds the computer must
read the spacecraft's position from the inertial measurement
unit. If it fails to do so, it will hopelessly lose track of
which way it's pointed and how fast it is going. Real-time
programmers live under these demanding constraints and,
especially given the limitations of a computer such as the AGC,
must deploy all of their cleverness to meet them without fail,
whatever happens, including transient power failures,
flaky readings from instruments, user errors, and
completely unanticipated “unknown unknowns”.
The software which ran in the Lunar Module AGCs for Apollo
lunar landing missions was called LUMINARY, and in its final
form (version 210) used on Apollo 15, 16, and 17, consisted
of around 36,000 lines of code (a mix of assembly language
and interpretive code which implemented high-level operations),
of which Don Eyles wrote in excess of 2,200 lines, responsible
for the lunar landing from the start of braking from lunar
orbit through touchdown on the Moon. This was by far the most
dynamic phase of an Apollo mission, and the most demanding on
the limited resources of the AGC, which was pushed to around
90% of its capacity during the final landing phase where the
astronauts were selecting the landing spot and guiding the
Lunar Module toward a touchdown. The margin was razor-thin,
and that's assuming everything went as planned. But this was
not always the case.
It was when the unexpected happened that the genius of the AGC
software and its ability to make the most of the severely
limited resources at its disposal became apparent. As Apollo 11
approached the lunar surface, a series of five program alarms:
codes 1201 and 1202, interrupted the display of altitude and
vertical velocity being monitored by Buzz Aldrin and read off
to guide Neil Armstrong in flying to the landing spot. These
codes both indicated out-of-memory conditions in the AGC's
scarce read-write memory. The 1201 alarm was issued when
all five of the 44-word vector accumulator (VAC) areas were in use
when another program requested to use one, and 1202 signalled
exhaustion of the eight 12-word core sets required by
each running job. The computer had a single processor and
could execute only one task at a time, but its operating system
allowed lower priority tasks to be interrupted in order to
service higher priority ones, such as the time-critical autopilot
function and reading the inertial platform every two seconds.
Each suspended lower-priority job used up a core set and,
if it employed the interpretive mathematics library, a VAC,
so exhaustion of these resources usually meant the computer was
trying to do too many things at once. Task priorities
were assigned so the most critical functions would be completed
on time, but computer overload signalled something seriously
wrong—a condition in which it was impossible to guarantee
all essential work was getting done.
In this case, the computer would throw up its hands, issue a
program alarm, and restart. But this couldn't be a lengthy
reboot like customers of personal computers with millions of
times the AGC's capacity tolerate half a century later. The
critical tasks in the AGC's software incorporated restart
protection, in which they would frequently checkpoint their
current state, permitting them to resume almost instantaneously
after a restart. Programmers estimated around 4% of the AGC's
program memory was devoted to restart protection, and some
questioned its worth. On Apollo 11, it would save the landing
mission.
Shortly after the Lunar Module's landing radar locked onto
the lunar surface, Aldrin keyed in the code to monitor its
readings and immediately received a 1202 alarm: no core sets
to run a task; the AGC restarted. On the communications
link Armstrong called out “It's a 1202.” and
Aldrin confirmed “1202.”. This was followed by
fifteen seconds of silence on the “air to ground”
loop, after which Armstrong broke in with “Give us a
reading on the 1202 Program alarm.” At this point,
neither the astronauts nor the support team in Houston
had any idea what a 1202 alarm was or what it might mean
for the mission. But the nefarious simulation supervisors
had cranked in such “impossible” alarms in
earlier training sessions, and controllers had developed
a rule that if an alarm was infrequent and the Lunar Module
appeared to be flying normally, it was not a reason to abort the
descent.
At the Instrumentation Laboratory in Cambridge, Massachusetts,
Don Eyles and his colleagues knew precisely what a 1202 was and
found it was deeply disturbing. The AGC software had been
carefully designed to maintain a 10% safety margin under the
worst case conditions of a lunar landing, and 1202 alarms had
never occurred in any of their thousands of simulator runs using
the same AGC hardware, software, and sensors as Apollo 11's
Lunar Module. Don Eyles' analysis, in real time, just after a
second 1202 alarm occurred thirty seconds later, was:
Again our computations have been flushed and the LM is still flying. In Cambridge someone says, “Something is stealing time.” … Some dreadful thing is active in our computer and we do not know what it is or what it will do next. Unlike Garman [AGC support engineer for Mission Control] in Houston I know too much. If it were in my hands, I would call an abort.
As the Lunar Module passed 3000 feet, another alarm, this time a 1201—VAC areas exhausted—flashed. This is another indication of overload, but of a different kind. Mission control immediately calls up “We're go. Same type. We're go.” Well, it wasn't the same type, but they decided to press on. Descending through 2000 feet, the DSKY (computer display and keyboard) goes blank and stays blank for ten agonising seconds. Seventeen seconds later another 1202 alarm, and a blank display for two seconds—Armstrong's heart rate reaches 150. A total of five program alarms and resets had occurred in the final minutes of landing. But why? And could the computer be trusted to fly the return from the Moon's surface to rendezvous with the Command Module? While the Lunar Module was still on the lunar surface Instrumentation Laboratory engineer George Silver figured out what happened. During the landing, the Lunar Module's rendezvous radar (used only during return to the Command Module) was powered on and set to a position where its reference timing signal came from an internal clock rather than the AGC's master timing reference. If these clocks were in a worst case out of phase condition, the rendezvous radar would flood the AGC with what we used to call “nonsense interrupts” back in the day, at a rate of 800 per second, each consuming one 11.72 microsecond memory cycle. This imposed an additional load of more than 13% on the AGC, which pushed it over the edge and caused tasks deemed non-critical (such as updating the DSKY) not to be completed on time, resulting in the program alarms and restarts. The fix was simple: don't enable the rendezvous radar until you need it, and when you do, put the switch in the position that synchronises it with the AGC's clock. But the AGC had proved its excellence as a real-time system: in the face of unexpected and unknown external perturbations it had completed the mission flawlessly, while alerting its developers to a problem which required their attention. The creativity of the AGC software developers and the merit of computer systems sufficiently simple that the small number of people who designed them completely understood every aspect of their operation was demonstrated on Apollo 14. As the Lunar Module was checked out prior to the landing, the astronauts in the spacecraft and Mission Control saw the abort signal come on, which was supposed to indicate the big Abort button on the control panel had been pushed. This button, if pressed during descent to the lunar surface, immediately aborted the landing attempt and initiated a return to lunar orbit. This was a “one and done” operation: no Microsoft-style “Do you really mean it?” tea ceremony before ending the mission. Tapping the switch made the signal come and go, and it was concluded the most likely cause was a piece of metal contamination floating around inside the switch and occasionally shorting the contacts. The abort signal caused no problems during lunar orbit, but if it should happen during descent, perhaps jostled by vibration from the descent engine, it would be disastrous: wrecking a mission costing hundreds of millions of dollars and, coming on the heels of Apollo 13's mission failure and narrow escape from disaster, possibly bring an end to the Apollo lunar landing programme. The Lunar Module AGC team, with Don Eyles as the lead, was faced with an immediate challenge: was there a way to patch the software to ignore the abort switch, protecting the landing, while still allowing an abort to be commanded, if necessary, from the computer keyboard (DSKY)? The answer to this was obvious and immediately apparent: no. The landing software, like all AGC programs, ran from read-only rope memory which had been woven on the ground months before the mission and could not be changed in flight. But perhaps there was another way. Eyles and his colleagues dug into the program listing, traced the path through the logic, and cobbled together a procedure, then tested it in the simulator at the Instrumentation Laboratory. While the AGC's programming was fixed, the AGC operating system provided low-level commands which allowed the crew to examine and change bits in locations in the read-write memory. Eyles discovered that by setting the bit which indicated that an abort was already in progress, the abort switch would be ignored at the critical moments during the descent. As with all software hacks, this had other consequences requiring their own work-arounds, but by the time Apollo 14's Lunar Module emerged from behind the Moon on course for its landing, a complete procedure had been developed which was radioed up from Houston and worked perfectly, resulting in a flawless landing. These and many other stories of the development and flight experience of the AGC lunar landing software are related here by the person who wrote most of it and supported every lunar landing mission as it happened. Where technical detail is required to understand what is happening, no punches are pulled, even to the level of bit-twiddling and hideously clever programming tricks such as using an overflow condition to skip over an EXTEND instruction, converting the following instruction from double precision to single precision, all in order to save around forty words of precious non-bank-switched memory. In addition, this is a personal story, set in the context of the turbulent 1960s and early ’70s, of the author and other young people accomplishing things no humans had ever before attempted. It was a time when everybody was making it up as they went along, learning from experience, and improvising on the fly; a time when a person who had never written a line of computer code would write, as his first program, the code that would land men on the Moon, and when the creativity and hard work of individuals made all the difference. Already, by the end of the Apollo project, the curtain was ringing down on this era. Even though a number of improvements had been developed for the LM AGC software which improved precision landing capability, reduced the workload on the astronauts, and increased robustness, none of these were incorporated in the software for the final three Apollo missions, LUMINARY 210, which was deemed “good enough” and the benefit of the changes not worth the risk and effort to test and incorporate them. Programmers seeking this kind of adventure today will not find it at NASA or its contractors, but instead in the innovative “New Space” and smallsat industries. - Ferguson, Niels and Bruce Schneier. Practical Cryptography. Indianapolis: Wiley Publishing, 2003. ISBN 0-471-22357-3.
- This is one of the best technical books I have read in the last decade. Those who dismiss this volume as “Applied Cryptography Lite” are missing the point. While the latter provides in-depth information on a long list of cryptographic systems (as of its 1996 publication date), Practical Cryptography provides specific recommendations to engineers charged with implementing secure systems based on the state of the art in 2003, backed up with theoretical justification and real-world experience. The book is particularly effective in conveying just how difficult it is to build secure systems, and how “optimisation”, “features”, and failure to adopt a completely paranoid attitude when evaluating potential attacks on the system can lead directly to the bull's eye of disaster. Often-overlooked details such as entropy collection to seed pseudorandom sequence generators, difficulties in erasing sensitive information in systems which cache data, and vulnerabilities of systems to timing-based attacks are well covered here.
- Ferry, Georgina. A Computer Called LEO. London: Fourth Estate, 2003. ISBN 1-84115-185-8.
- I'm somewhat of a computer history buff (see my Babbage and UNIVAC pages), but I knew absolutely nothing about the world's first office computer before reading this delightful book. On November 29, 1951 the first commercial computer application went into production on the LEO computer, a vacuum tube machine with mercury delay line memory custom designed and built by—(UNIVAC? IBM?)—nope: J. Lyons & Co. Ltd. of London, a catering company which operated the Lyons Teashops all over Britain. LEO was based on the design of the Cambridge EDSAC, but with additional memory and modifications for commercial work. Many present-day disasters in computerisation projects could be averted from the lessons of Lyons, who not only designed, built, and programmed the first commercial computer from scratch but understood from the outset that the computer must fit the needs and operations of the business, not the other way around, and managed thereby to succeed on the very first try. LEO remained on the job for Lyons until January 1965. (How many present-day computers will still be running 14 years after they're installed?) A total of 72 LEO II and III computers, derived from the original design, were built, and some remained in service as late as 1981. The LEO Computers Society maintains an excellent Web site with many photographs and historical details.
- Feynman, Richard P. Feynman Lectures on Computation. Edited by Anthony J.G. Hey and Robin W. Allen. Reading MA: Addison-Wesley, 1996. ISBN 0-201-48991-0.
- This book is derived from Feynman's lectures on the physics of computation in the mid 1980s at CalTech. A companion volume, Feynman and Computation (see September 2002), contains updated versions of presentations by guest lecturers in this course.
- Fulton, Steve and Jeff Fulton. HTML5 Canvas. Sebastopol, CA: O'Reilly, 2013. ISBN 978-1-4493-3498-7.
-
I only review computer books if I've read them in their entirety,
as opposed to using them as references while working on
projects. For much of 2017 I've been living with this book
open, referring to it as I performed a comprehensive overhaul
of my Fourmilab site, and I just realised that
by now I have actually read every page, albeit not in linear
order, so a review is in order; here goes.
The original implementation of World Wide Web supported only text
and, shortly thereafter, embedded images in documents. If you
wanted to do something as simple as embed an audio or video clip,
you were on your own, wading into a morass of browser- and
platform-specific details, plug-ins the user may have to install
and then forever keep up to date, and security holes due to all of this
non-standard and often dodgy code. Implementing interactive
content on the Web, for example scientific simulations for
education, required using an embedded language such as
Java,
whose initial bright promise of “Write once, run anywhere”
quickly added the rejoinder “—yeah, right” as
bloat in the language, incessant security problems, cross-platform
incompatibilities, the need for the user to forever keep external
plug-ins updated lest existing pages cease working, caused Java to
be regarded as a joke—a cruel joke upon those who developed
Web applications based upon it. By the latter half of the 2010s,
the major browsers had either discontinued support for Java or
announced its removal in future releases.
Fortunately, in 2014 the HTML5
standard was released. For the first time, native, standardised
support was added to the Web's fundamental document format to
support embedded audio, video, and interactive content, along with
Application Programming Interfaces (APIs) in the
JavaScript
language, interacting with the document via the
Document
Object Model (DOM), which has now been incorporated into the
HTML5 standard. For the first time it became possible, using only
standards officially adopted by the
World
Wide Web Consortium, to create interactive Web pages
incorporating multimedia content. The existence of this standard
provides a strong incentive for browser vendors to fully implement
and support it, and increases the confidence of Web developers that
pages they create which are standards-compliant will work on the
multitude of browsers, operating systems, and hardware platforms
which exist today.
(That encomium apart, I find much to dislike about HTML5. In my
opinion its sloppy syntax [not requiring quotes on tag
attributes nor the closing of many tags] is a great step
backward from
XHTML 1.0,
which strictly conforms to XML syntax and can be parsed by a
simple and generic XML parser, without the Babel-sized tower of
kludges and special cases which are required to accommodate the
syntactic mumbling of HTML5. A machine-readable language should
be easy to read and parse by a machine, especially in
an age where only a small minority of Web content creators
actually write HTML themselves, as opposed to using a content
management system of some kind. Personally, I continue to use
XHTML 1.0 for all content on my Web site which does not
require the new features in HTML5, and I observe that the
home page of the World Wide Web
Consortium is, itself, in XHTML 1.0 Strict. And there's
no language version number in the header of an HTML5
document. Really—what's up with that? But HTML5
is the standard we've got, so it's the standard we have to use
in order to benefit from the capabilities it provides: onward.)
One of the most significant new features in HTML5 is its support
for the Canvas
element. A canvas is a rectangular area within a page which is
treated as an RGBA
bitmap (the “A” denotes “alpha”, which
implements transparency for overlapping objects). A canvas is just
what its name implies: a blank area on which you can draw. The drawing
is done in JavaScript code via the Canvas API, which is documented
in this book, along with tutorials and abundant examples which can be
downloaded
from the publisher's Web site. The API provides the usual
functions of a two-dimensional drawing model, including lines, arcs,
paths, filled objects, transformation matrices, clipping, and
colours, including gradients. A text API allows drawing text on the
canvas, using a subset of
CSS
properties to define fonts and their display attributes.
Bitmap images may be painted on the canvas, scaled and rotated,
if you wish, using the transformation matrix. It is also possible
to retrieve the pixel data from a canvas or portion of it,
manipulate it at low-level, and copy it back to that or another
canvas using JavaScript
typed
arrays.
This allows implementation of arbitrary image processing. You
might think that pixel-level image manipulation in JavaScript
would be intolerably slow, but with modern implementations of
JavaScript in current browsers, it often runs within a factor of
two of the speed of optimised C code and, unlike the C code, works
on any platform from within a Web page which requires no twiddling
by the user to build and install on their computer.
The canvas API allows capturing mouse and keyboard events,
permitting user interaction. Animation is implemented using
JavaScript's standard setTimeout method. Unlike
some other graphics packages, the canvas API does not maintain
a display list or refresh buffer. It is the responsibility of
your code to repaint the image on the canvas from scratch
whenever it changes. Contemporary browsers buffer the image
under construction to prevent this process from being seen by
the user.
HTML5 audio and video are not strictly part of the canvas
facility (although you can display a video on a canvas), but
they are discussed in depth here, each in its own chapter.
Although the means for embedding this content into Web pages
are now standardised, the file formats for audio and video are,
more than a quarter century after the creation of the Web,
“still evolving”. There is sage advice for
developers about how to maximise portability of pages across
browsers and platforms.
Two chapters, 150 pages of this 750 page book (don't be
intimidated by its length—a substantial fraction is code
listings you don't need to read unless you're interested in the
details), are devoted to game development using the HTML5 canvas
and multimedia APIs. A substantial part of this covers topics
such as collision detection, game physics, smooth motion, and
detecting mouse hits in objects, which are generic subjects
in computer graphics and not specific to its HTML5 implementation.
Reading them, however, may give you some tips useful in
non-game applications.
Projects at Fourmilab which now use HTML5 canvas are:
- The Probability Pipe Organ
- RetroPsychoKinesis Experiments
- Terranova: Planet Maker
- Orbits in Strongly Curved Spacetime
- Cellular Automata Laboratory
- The Analytical Engine (curve drawing apparatus)
- HotBits (animated logo)
- Gershenfeld, Neil. Fab. New York: Basic Books, 2005. ISBN 0-465-02745-8.
-
Once, every decade or so, you encounter a book which empowers
you in ways you never imagined before you opened it, and
ultimately changes your life. This is one of those books.
I am who I am (not to sound too much like Popeye) largely
because in the fall of 1967 I happened to read Daniel McCracken's
FORTRAN book and realised that there was
nothing complicated at all about programming computers—it was a
vocational skill that anybody could learn, much like
operating a machine tool. (Of course, as you get deeper into the
craft, you discover there is a great body of theory to master, but
there's much you can accomplish if you're willing to work hard and
learn on the job before you tackle the more abstract aspects of the
art.) But this was not only something that I could do but,
more importantly, I could learn by doing—and that's how I decided
to spend the rest of my professional life and I've never regretted having
done so. I've never met a genuinely creative person who wished to
spend a nanosecond in a classroom downloading received wisdom at
dial-up modem bandwidth. In fact, I suspect the absence of such
people in the general population is due to the pernicious effects
of the Bismarck worker-bee indoctrination to which the youth of most
“developed” societies are subjected today.
We all know that, some day, society will pass through the nanotechnological
singularity, after which we'll be
eternally free,
eternally young,
immortal, and incalculably rich: hey—works for me! But few
people realise that if
the age of globalised mass production is analogous to that of
mainframe computers
and if the
desktop
nano-fabricator is
equivalent to today's personal supercomputer, we're already
in the equivalent of the minicomputer age of personal fabrication.
Remember minicomputers? Not too large, not too small, and hence difficult
to classify: too expensive for most people to buy, but within the
budget of groups far smaller than the governments and large
businesses who could afford mainframes.
The minicomputer age of personal fabrication is as messy as the
architecture of minicomputers of four decades before: there are lots
of different approaches, standards, interfaces, all mutually
incompatible: isn't innovation wonderful? Well, in this sense
no!
But it's here, now. For a sum in the tens of
thousands of U.S. dollars, it is now possible to equip a
“Fab Lab” which can make “almost anything”.
Such a lab can fit into a modestly sized room, and, provided with
electrical power and an Internet connection, can empower whoever
crosses its threshold to create whatever their imagination can
conceive. In just a few minutes, their dream can become
tangible hardware in the real world.
The personal computer revolution empowered almost anybody (at least
in the developed world) to create whatever information processing
technology their minds could imagine, on their own, or in collaboration
with others. The Internet expanded the scope of this collaboration
and connectivity around the globe: people who have never met one another
are now working together to create software which will be used by
people who have never met the authors to everybody's mutual benefit. Well,
software is cool, but imagine if this extended to stuff. That's
what Fab is about. SourceForge
currently hosts more than 135,500 software development projects—imagine
what will happen when StuffForge.net (the name is still available, as I
type this sentence!) hosts millions of OpenStuff things you can
download to your local Fab Lab, make, and incorporate
into inventions of your own imagination. This is the grand roll-back of
the industrial revolution, the negation of globalisation: individuals,
all around the world, creating for themselves products tailored to their
own personal needs and those of their communities, drawing upon the freely
shared wisdom and experience of their peers around the globe. What a beautiful
world it will be!
Cynics will say, “Sure, it can work at MIT—you have one of the most
talented student bodies on the planet, supported by a faculty which excels in
almost every discipline, and an industrial plant with bleeding edge fabrication
technologies of all kinds.” Well, yes, it works there. But the most inspirational
thing about this book is that it seems to work everywhere: not just at MIT
but also in South Boston, rural India, Norway far north of the Arctic Circle,
Ghana, and Costa Rica—build it and they will make. At times the
author seems unduly amazed that folks without formal education and the advantages
of a student at MIT can imagine, design, fabricate, and apply a solution to
a problem in their own lives. But we're human beings—tool-making
primates who've prospered by figuring things out and finding ways to make
our lives easier by building tools. Is it so surprising that putting the
most modern tools into the hands of people who daily confront the most
fundamental problems of existence (access to clean water, food, energy, and
information) will yield innovations which surprise even professors at
MIT?
This book is so great, and so inspiring, that I will give the author a
pass on his clueless attack on AutoCAD's (never attributed) DXF file
format on pp. 46–47, noting simply that the answer to why
it's called “DXF” is that Lotus had already used
“DIF” for their spreadsheet interchange files and
we didn't want to create confusion with their file format, and that
the reason there's more than one code for an X co-ordinate is that
many geometrical objects require more than one X co-ordinate to define them
(well, duh).
The author also totally gets what I've been talking about
since Unicard and
even before that as “Gizmos”, that
every single device in the world, and every button on every
device will eventually have its own (IPv6) Internet address and be
able to interact with every other such object in every way that makes
sense. I envisioned MIDI networks as the cheapest way to implement
this bottom-feeder light-switch to light-bulb network; the author,
a decade later, opts for a PCM “Internet 0”—works for
me. The medium doesn't matter; it's that the message makes it end
to end so cheaply that you can ignore the cost of the interconnection
that ultimately matters.
The author closes the book with the invitation:
Finally, demand for fab labs as a research project, as a collection of capabilities, as a network of facilities, and even as a technological empowerment movement is growing beyond what can be handled by the initial collection of people and institutional partners that were involved in launching them. I/we welcome your thoughts on, and participation in, shaping their future operational, organizational, and technological form.
Well, I am but a humble programmer, but here's how I'd go about it. First of all, I'd create a “Fabrication Trailer“ which could visit every community in the United States, Canada, and Mexico; I'd send it out on the road in every MIT vacation season to preach the evangel of “make” to every community it visited. In, say, one of eighty of such communities, one would find a person who dreamed of this happening in his or her lifetime who was empowered by seeing it happen; provide them a template which, by writing a cheque, can replicate the fab and watch it spread. And as it spreads, and creates wealth, it will spawn other Fab Labs. Then, after it's perfected in a couple of hundred North American copies, design a Fab Lab that fits into an ocean cargo container and can be shipped anywhere. If there isn't electricity and Internet connectivity, also deliver the diesel generator or solar panels and satellite dish. Drop these into places where they're most needed, along with a wonk who can bootstrap the locals into doing things with these tools which astound even those who created them. Humans are clever, tool-making primates; give us the tools to realise what we imagine and then stand back and watch what happens! The legacy media bombard us with conflict, murder, and mayhem. But the future is about creation and construction. What does An Army of Davids do when they turn their creativity and ingenuity toward creating solutions to problems perceived and addressed by individuals? Why, they'll call it a renaissance! And that's exactly what it will be. For more information, visit the Web site of The Center for Bits and Atoms at MIT, which the author directs. Fab Central provides links to Fab Labs around the world, the machines they use, and the open source software tools you can download and start using today. - Gilder, George. Life after Google. Washington: Regnery Publishing, 2018. ISBN 978-1-62157-576-4.
-
In his 1990 book Life after Television,
George Gilder predicted that the personal computer, then mostly boxes
that sat on desktops and worked in isolation from one another,
would become more personal, mobile, and be used more to communicate
than to compute. In the 1994 revised edition of the book, he
wrote. “The most common personal computer of the next decade will be
a digital cellular phone with an IP address … connecting
to thousands of databases of all kinds.” In contemporary
speeches he expanded on the idea, saying, “it will be as
portable as your watch and as personal as your wallet; it will
recognize speech and navigate streets; it will collect your
mail, your news, and your paycheck.” In 2000, he
published Telecosm, where
he forecast that the building out of a fibre optic communication
infrastructure and the development of successive generations of
spread spectrum digital mobile communication technologies would
effectively cause the cost of communication bandwidth (the quantity
of data which can be transmitted in a given time) to asymptotically
approach zero, just as the ability to pack more and more transistors
on microprocessor and memory chips was doing for computing.
Clearly, when George Gilder forecasts the future of computing,
communication, and the industries and social phenomena that
spring from them, it's wise to pay attention. He's not
infallible: in 1990 he predicted that “in the world of
networked computers, no one would have to see an advertisement
he didn't want to see”. Oh, well. The
very difference between that happy vision and the
advertisement-cluttered world we inhabit today, rife with
bots, malware, scams, and serial large-scale security breaches
which compromise the personal data of millions of people and
expose them to identity theft and other forms of fraud is the
subject of this book: how we got here, and how technology is
opening a path to move on to a better place.
The Internet was born with decentralisation as a central
concept. Its U.S. government-funded precursor,
ARPANET,
was intended to research and demonstrate the technology
of packet
switching, in which dedicated communication lines
from point to point (as in the telephone network) were
replaced by switching packets, which can represent all
kinds of data—text, voice, video, mail, cat
pictures—from source to destination over shared high-speed
data links. If the network had multiple paths from source
to destination, failure of one data link would simply cause
the network to reroute traffic onto a working path, and
communication protocols would cause any packets lost in the
failure to be automatically re-sent, preventing loss of
data. The network might degrade and deliver data more slowly
if links or switching hubs went down, but everything
would still get through.
This was very attractive to military planners in the Cold
War, who worried about a nuclear attack decapitating their
command and control network by striking one or a few
locations through which their communications funnelled. A
distributed network, of which ARPANET was the prototype,
would be immune to this kind of top-down attack because
there was no top: it was made up of peers, spread all over
the landscape, all able to switch data among themselves
through a mesh of interconnecting links.
As the ARPANET grew into the Internet and expanded from a small
community of military, government, university, and large
company users into a mass audience in the 1990s, this
fundamental architecture was preserved, but in practice the
network bifurcated into a two tier structure. The top tier
consisted of the original ARPANET-like users, plus
“Internet Service Providers” (ISPs), who had
top-tier (“backbone”) connectivity, and then
resold Internet access to their customers, who mostly
initially connected via dial-up modems. Over time, these customers
obtained higher bandwidth via cable television connections,
satellite dishes, digital subscriber lines (DSL) over
the wired telephone network, and, more recently, mobile
devices such as cellular telephones and tablets.
The architecture of the Internet remained the same, but this
evolution resulted in a weakening of its peer-to-peer
structure. The approaching exhaustion
of 32 bit Internet addresses
(IPv4) and
the slow deployment of its successor
(IPv6)
meant most small-scale Internet users did not have a
permanent address where others could contact them. In an
attempt to shield users from the flawed security model and
implementation of the software they ran, their Internet
connections were increasingly placed behind firewalls and subjected to
Network Address Translation (NAT), which made it impossible
to establish peer to peer connections without a third party
intermediary (which, of course, subverts the design goal of
decentralisation). While on the ARPANET and the original
Internet every site was a peer of every other (subject only
to the speed of their network connections and computer power
available to handle network traffic), the network population
now became increasingly divided into producers or publishers (who
made information available), and consumers (who used the network
to access the publishers' sites but did not publish themselves).
While in the mid-1990s it was easy (or as easy as anything
was in that era) to set up your own Web server and publish
anything you wished, now most small-scale users were forced to employ
hosting services operated by the publishers to make their
content available. Services such as AOL, Myspace, Blogger,
Facebook, and YouTube were widely used by
individuals and companies to host their content, while
those wishing their own apparently independent Web presence
moved to hosting providers who supplied, for a fee, the
servers, storage, and Internet access used by the site.
All of this led to a centralisation of data on the Web,
which was accelerated by the emergence of the high speed
fibre optic links and massive computing power upon which Gilder had
based his 1990 and 2000 forecasts. Both of these
came with great economies of scale: it cost a company
like Google or Amazon much less per unit of computing
power or network bandwidth to build a large, industrial-scale
data centre located where electrical power and cooling
were inexpensive and linked to the Internet backbone
by multiple fibre optic channels, than it cost an individual
Internet user or small company with their own server
on premises and a modest speed link to an ISP. Thus it
became practical for these Goliaths of the Internet to
suck up everybody's data and resell their computing power
and access at attractive prices.
As a example of the magnitude of the economies of scale we're
talking about, when I migrated the hosting of my
Fourmilab.ch site from my own
on-site servers and Internet connection to an Amazon Web
Services data centre, my monthly bill for hosting the site
dropped by a factor of fifty—not fifty percent,
one fiftieth the cost, and you can bet Amazon's
making money on the deal.
This tremendous centralisation is the antithesis of the concept
of ARPANET. Instead of a worldwide grid of redundant data links
and data distributed everywhere, we have a modest number of huge
data centres linked by fibre optic cables carrying traffic for
millions of individuals and enterprises. A couple of submarines
full of
Trident
D5s would probably suffice to reset the world, computer
network-wise, to 1970.
As this concentration was occurring, the same companies who were
building the data centres were offering more and more services
to users of the Internet: search engines; hosting of blogs,
images, audio, and video; E-mail services; social networks of
all kinds; storage and collaborative working tools;
high-resolution maps and imagery of the world; archives of data
and research material; and a host of others. How was all of
this to be paid for? Those giant data centres, after all,
represent a capital investment of tens of billions of
dollars, and their electricity bills are comparable to those of
an aluminium smelter. Due to the architecture of the Internet
or, more precisely, missing pieces of the puzzle, a fateful
choice was made in the early days of the build-out of these
services which now pervade our lives, and we're all
paying the price for it. So far, it has allowed the few
companies in this data oligopoly to join the ranks of the
largest, most profitable, and most highly valued enterprises in
human history, but they may be built on a flawed business model
and foundation vulnerable to disruption by software and
hardware technologies presently emerging.
The basic business model of what we might call the “consumer
Internet” (as opposed to businesses who pay to host their
Web presence, on-line stores, etc.) has, with few exceptions,
evolved to be what the author calls the “Google model”
(although it predates Google): give the product away and make money
by afflicting its users with advertisements (which are increasingly
targeted to them through information collected from the user's
behaviour on the network through intrusive tracking mechanisms).
The fundamental flaws of this are apparent to anybody who uses
the Internet: the constant clutter of advertisements, with
pop-ups, pop-overs, auto-play video and audio, flashing banners,
incessant requests to allow tracking “cookies” or
irritating notifications, and the consequent arms race between
ad blockers and means to circumvent them, with browser developers
(at least those not employed by those paid by the advertisers,
directly or indirectly) caught in the middle.
There are even absurd Web sites which charge a subscription fee
for “membership” and then bombard these paying
customers with advertisements that insult their intelligence.
But there is a fundamental problem with
“free”—it destroys the most important channel
of communication between the vendor of a product or service and
the customer: the price the customer is willing to pay.
Deprived of this information, the vendor is in the same position
as a factory manager in a centrally planned economy who has no
idea how many of each item to make because his orders are handed
down by a planning bureau equally clueless about what is
needed in the absence of a price signal. In the end, you have
freight cars of typewriter ribbons lined up on sidings while
customers wait in line for hours in the hope of buying a
new pair of shoes. Further, when the user is not the customer
(the one who pays), and especially when a “free”
service verges on monopoly status like Google search, Gmail,
Facebook, and Twitter, there is little incentive for providers
to improve the user experience or be responsive to user requests
and needs. Users are subjected to the endless torment of buggy
“beta” releases, capricious change for the sake of
change, and compromises in the user experience on behalf of the
real customers—the advertisers. Once again, this mirrors
the experience of centrally-planned economies where the market
feedback from price is absent: to appreciate this, you need only
compare consumer products from the 1970s and 1980s manufactured
in the Soviet Union with those from Japan.
The fundamental flaw in Karl Marx's economics was his
belief that the industrial revolution of his time would produce
such abundance of goods that the problem would shift from
“production amid scarcity” to “redistribution
of abundance”. In the author's view, the neo-Marxists of
Silicon Valley see the exponentially growing technologies of
computing and communication providing such abundance that they
can give away its fruits in return for collecting and monetising
information collected about their users (note, not
“customers”: customers are those who pay for the
information so collected). Once you grasp this, it's
easier to understand the politics of the barons of Silicon
Valley.
The centralisation of data and information flow in these
vast data silos creates another threat to which a
distributed system is immune: censorship or manipulation of
information flow, whether by a coercive government or
ideologically-motivated management of the companies who
provide these “free” services. We may never
know who first said “The Internet treats censorship as
damage and routes around it” (the quote has been
attributed to numerous people, including two personal
friends, so I'm not going there), but it's profound: the
original decentralised structure of the ARPANET/Internet
is as robust against censorship as it is in the face of
nuclear war. If one or more nodes on the network start to
censor information or refuse to forward it on communication
links it controls, the network routing protocols simply assume
that node is down and send data around it through other nodes
and paths which do not censor it. On a network with a
multitude of nodes and paths among them, owned by a large
and diverse population of operators, it is extraordinarily
difficult to shut down the flow of information from a given
source or viewpoint; there will almost always be an
alternative route that gets it there. (Cryptographic
protocols and secure and verified identities can similarly
avoid the alteration of information in transit or forging
information and attributing it to a different originator;
I'll discuss that later.) As with physical damage,
top-down censorship does not work because there's no top.
But with the current centralised Internet, the owners and
operators of these data silos have enormous power to put their
thumbs on the scale, tilting opinion in their favour and
blocking speech they oppose. Google can push down the page
rank of information sources of which they disapprove, so
few users will find them. YouTube can “demonetise”
videos because they dislike their content,
cutting off their creators' revenue stream overnight
with no means of appeal, or they can outright ban creators
from the platform and remove their existing content. Twitter
routinely “shadow-bans” those with whom they disagree,
causing their tweets to disappear into the void, and outright
banishes those more vocal. Internet payment processors and
crowd funding sites enforce explicit ideological litmus tests
on their users, and revoke long-standing commercial relationships
over legal speech. One might restate the original observation
about the Internet as “The centralised Internet treats
censorship as an opportunity and says,
‘Isn't it great!’ ” Today there's
a top, and those on top control the speech of everything that
flows through their data silos.
This pernicious centralisation and “free” funding
by advertisement (which is fundamentally plundering users'
most precious possessions: their time and attention) were
in large part the consequence of the Internet's lacking three
fundamental architectural layers: security, trust, and transactions.
Let's explore them.
Security. Essential to any useful communication
system, security simply means that communications between
parties on the network cannot be intercepted by third parties,
modified en route, or otherwise manipulated (for example, by
changing the order in which messages are received). The
communication protocols of the Internet, based on the
OSI model,
had no explicit security layer. It was expected to be
implemented outside the model, across the layers of
protocol. On today's Internet, security has been bolted-on,
largely through the
Transport
Layer Security (TLS) protocols (which, due to history, have
a number of other commonly used names, and are most often
encountered in the “https:” URLs by
which users access Web sites). But because it's bolted on, not
designed in from the bottom-up, and because it “just grew”
rather than having been designed in, TLS has been the locus of
numerous security flaws which put software that employs it
at risk. Further, TLS is a tool which must be used by application
designers with extreme care in order to deliver security to their
users. Even if TLS were completely flawless, it is very easy to
misuse it in an application and compromise users' security.
Trust. As indispensable as security is knowing to whom you're
talking. For example, when you connect to your bank's Web site,
how do you know you're actually talking to their server and not
some criminal whose computer has spoofed your computer's domain
name system server to intercept your communications and who, the
moment you enter your password, will be off and running to empty
your bank accounts and make your life a living Hell? Once again,
trust has been bolted on to the existing Internet through a
rickety system of “certificates” issued mostly by
large companies for outrageous fees. And, as with anything
centralised, it's vulnerable: in 2016, one of the
top-line certificate vendors was compromised, requiring myriad
Web sites (including this one) to re-issue their security
certificates.
Transactions. Business is all about
transactions; if you aren't doing transactions, you aren't
in business or, as Gilder puts it, “In business, the
ability to conduct transactions is not optional. It is the
way all economic learning and growth occur. If your product is
‘free,’ it is not a product, and you are not in
business, even if you can extort money from so-called
advertisers to fund it.” The present-day Internet
has no transaction layer, even bolted on. Instead, we have
more silos and bags hanging off the side of the Internet
called PayPal, credit card processing companies, and the
like, which try to put a Band-Aid over the suppurating
wound which is the absence of a way to send money over the
Internet in a secure, trusted, quick, efficient, and
low-overhead manner. The need for this was perceived long
before ARPANET. In
Project
Xanadu, founded by
Ted Nelson
in 1960, rule 9 of the
“original 17 rules” was, “Every document can
contain a royalty mechanism at any desired degree of granularity
to ensure payment on any portion accessed, including virtual
copies (‘transclusions’) of all or part of the
document.” While defined in terms of documents and
quoting, this implied the existence of a
micropayment
system which would allow compensating authors and publishers
for copies and quotations of their work with a granularity as
small as one character, and could easily be extended to cover
payments for products and services. A micropayment system must
be able to handle very small payments without crushing
overhead, extremely quickly, and transparently (without the
Japanese tea ceremony that buying something on-line involves
today). As originally envisioned by Ted Nelson, as you read
documents, their authors and publishers would be automatically
paid for their content, including payments to the originators of
material from others embedded within them. As long as the total
price for the document was less than what I termed the user's
“threshold of paying”, this would be completely
transparent (a user would set the threshold in the browser: if
zero, they'd have to approve all payments). There would be
no need for advertisements to support publication on a public
hypertext network (although publishers would, of course, be free
to adopt that model if they wished). If implemented in a
decentralised way, like the ARPANET, there would be no
central strangle point where censorship could be applied by
cutting off the ability to receive payments.
So, is it possible to remake the Internet, building in
security, trust, and transactions as the foundation, and replace
what the author calls the “Google system of the world”
with one in which the data silos are seen as obsolete,
control of users' personal data and work returns to their
hands, privacy is respected and the panopticon snooping of
today is seen as a dark time we've put behind us, and the
pervasive and growing censorship by plutocrat
ideologues and slaver governments becomes impotent and
obsolete? George Gilder responds “yes”, and
in this book identifies technologies already existing and
being deployed which can bring about this transformation.
At the heart of many of these technologies is the concept
of a blockchain,
an open, distributed ledger which records transactions or any
other form of information in a permanent, public, and verifiable
manner. Originally conceived as the transaction ledger for
the Bitcoin
cryptocurrency,
it provided the first means of solving the
double-spending
problem (how do you keep people from spending a unit of
electronic currency twice) without the need for a central server
or trusted authority, and hence without a potential choke-point
or vulnerability to attack or failure. Since the launch of
Bitcoin in 2009, blockchain technology has become a major area
of research, with banks and other large financial institutions,
companies such as IBM, and major university research groups
exploring applications with the goals of drastically reducing
transaction costs, improving security, and hardening systems
against single-point failure risks.
Applied to the Internet, blockchain technology can provide
security and trust (through the permanent publication of public
keys which identify actors on the network), and a transaction
layer able to efficiently and quickly execute micropayments
without the overhead, clutter, friction, and security risks of
existing payment systems. By necessity, present-day blockchain
implementations are add-ons to the existing Internet, but as the
technology matures and is verified and tested, it can move into
the foundations of a successor system, based on the same
lower-level protocols (and hence compatible with the installed
base), but eventually supplanting the patched-together
architecture of the
Domain
Name System,
certificate
authorities, and payment processors, all of which
represent vulnerabilities of the present-day Internet and
points at which censorship and control can be imposed. Technologies
to watch in these areas are:
As the bandwidth available to users on the edge of the network
increases through the deployment of fibre to the home and
enterprise and via
5G mobile
technology, the data transfer economy of scale of the great
data silos will begin to erode. Early in the Roaring Twenties,
the aggregate computing power and communication bandwidth on
the edge of the network will equal and eventually dwarf that
of the legacy data smelters of Google, Facebook, Twitter, and
the rest. There will no longer be any need for users to entrust
their data to these overbearing anachronisms and consent to multi-dozen
page “terms of service” or endure advertising
just to see their own content or share it with others. You
will be in possession of your own data, on your own server or
on space for which you freely contract with others, with backup and
other services contracted with any other provider on the
network. If your server has extra capacity, you can turn it
into money by joining the market for computing and storage
capacity, just as you take advantage of these resources when
required. All of this will be built on the new secure foundation,
so you will retain complete control over who can see your
data, no longer trusting weasel-worded promises made by
amorphous entities with whom you have no real contract to
guard your privacy and intellectual property rights. If
you wish, you can be paid for your content, with remittances
made automatically as people access it. More and more, you'll
make tiny payments for content which is no longer obstructed by
advertising and chopped up to accommodate more clutter. And
when outrage mobs of pink hairs and soybeards (each with their
own pronoun) come howling to ban you from the Internet, they'll
find nobody to shriek at and the kill switch rusting away in a
derelict data centre: your data will be in your own hands with
access through myriad routes.
Technologies moving in this direction include:
- Inrupt
- Brave Web browser and Basic Attention Token
- Golem distributed supercomputer
- OTOY RNDR rendering network
- Hall, Eldon C. Journey to the Moon: The History of the Apollo Guidance Computer. Reston, VA: AIAA, 1996. ISBN 1-56347-185-X.
- Hammersley, Ben. Content Syndication with RSS. Sebastopol, CA: O'Reilly, 2003. ISBN 0-596-00383-8.
- Sometimes the process of setting standards for the Internet just leaves you wanting to avert your eyes. The RSS standard, used by Web loggers, news sites, and other to provide “feeds” which apprise other sites of updates to their content is a fine example of what happens when standards go bad. At first, there was the idea that RSS would be fully RDF compliant, but then out came version 0.9 which used RDF incompletely and improperly. Then came 0.91, which stripped out RDF entirely, which was followed by version 1.0, which re-incorporated full support for RDF along with modules and XML namespaces. Two weeks later, along came version 0.92 (I'm not making this up), which extended 0.91 and remained RDF free. Finally, late in 2002, RSS 2.0 arrived, a further extension of 0.92, and not in any way based on 1.0—got that? Further, the different standards don't even agree on what “RSS” stands for; personally, I'd opt for “Ridiculous Standard Setting”. For the poor guy who simply wants to provide feeds to let folks know what's changed on a Web log or site, this is a huge mess, as it is for those who wish to monitor such feeds. This book recounts the tawdry history of RSS, provides examples of the various dialects, and provides useful examples for generating and using RSS feeds, as well as an overview of the RSS world, including syndication directories, aggregators, desktop feed reader tools, and Publish and Subscribe architectures.
- Hanson, Robin. The Age of Em. Oxford: Oxford University Press, 2016. ISBN 978-0-19-875462-6.
-
Many books, both fiction and nonfiction, have been devoted to the
prospects for and consequences of the advent of artificial
intelligence: machines with a general cognitive capacity which equals
or exceeds that of humans. While machines have already surpassed the
abilities of the best humans in certain narrow domains (for example,
playing games such as chess or go), you can't take a chess playing
machine and expect it to be even marginally competent at a task as
different as driving a car or writing a short summary of a newspaper
story—things most humans can do with a little experience. A
machine with “artificial general intelligence” (AGI) would
be as adaptable as humans, and able with practice to master a wide
variety of skills.
The usual scenario is that continued exponential progress in computing
power and storage capacity, combined with better understanding of how
the brain solves problems, will eventually reach a cross-over point
where artificial intelligence matches human capability. But since
electronic circuitry runs so much faster than the chemical signalling
of the brain, even the first artificial intelligences will be able to
work much faster than people, and, applying their talents to improving
their own design at a rate much faster than human engineers can
work, will result in an “intelligence explosion”, where
the capability of machine intelligence runs away and rapidly approaches
the physical limits of computation, far surpassing human cognition.
Whether the thinking of these super-minds will be any more comprehensible
to humans than quantum field theory is to a goldfish and whether humans
will continue to have a place in this new world and, if so, what it
may be, has been the point of departure for much speculation.
In the present book,
Robin Hanson,
a professor of economics at George Mason University,
explores a very different scenario.
What if the problem of artificial intelligence (figuring out how to
design software with capabilities comparable to the human brain)
proves to be much more difficult than many researchers assume,
but that we continue to experience exponential growth in computing
and our ability to map and understand the fine-scale structure of
the brain, both in animals and eventually humans? Then some time in
the next hundred years (and perhaps as soon as 2050), we may have the
ability to emulate the low-level operation of the brain with
an electronic computing substrate. Note that we need not have any idea
how the brain actually does what it does in order to do this: all we
need to do is understand the components (neurons, synapses,
neurotransmitters, etc.) and how they're connected together, then
build a faithful emulation of them on another substrate. This
emulation, presented with the same inputs (for example, the pulse
trains which encode visual information from the eyes and sound
from the ears), should produce the same outputs (pulse trains which
activate muscles, or internal changes within the brain which encode
memories).
Building an emulation of a brain is much like reverse-engineering an
electronic device. It's often unnecessary to know how the device
actually works as long as you can identify all of the components,
their values, and how they're interconnected. If you re-create that
structure, even though it may not look anything like the original
or use identical parts, it will still work the same as the prototype.
In the case of brain emulation, we're still not certain at what level
the emulation must operate nor how faithful it must be to the
original. This is something we can expect to learn
as more and more detailed emulations of parts of the brain are
built. The
Blue Brain Project
set out in 2005 to emulate one
neocortical
column
of the rat brain. This goal has now been achieved, and work is
progressing both toward more faithful simulation and expanding the
emulation to larger portions of the brain. For a sense of scale,
the human
neocortex consists
of about one million cortical columns.
In this work, the author assumes that emulation of the human brain
will eventually be achieved, then uses standard theories from the
physical sciences, economics, and social sciences to explore the
consequences and characteristics of the era in which emulations will
become common. He calls an emulation an “em”, and the
age in which they are the dominant form of sentient life on Earth
the “age of em”. He describes this future as
“troublingly strange”. Let's explore it.
As a starting point, assume that when emulation becomes possible, we
will not be able to change or enhance the operation of the emulated
brains in any way. This means that ems will have the same memory
capacity, propensity to forget things, emotions, enthusiasms,
psychological quirks and pathologies, and all of the idiosyncrasies of
the individual human brains upon which they are based. They will not
be the cold, purely logical, and all-knowing minds which science
fiction often portrays artificial intelligences to be. Instead, if you
know Bob well, and an emulation is made of his brain, immediately
after the emulation is started, you won't be able to distinguish Bob
from Em-Bob in a conversation. As the em continues to run and has its
own unique experiences, it will diverge from Bob based upon them, but,
we can expect much of its Bob-ness to remain.
But simply by being emulations, ems will inhabit a very different
world than humans, and can be expected to develop their own unique
society which differs from that of humans at least as much as the
behaviour of humans who inhabit an industrial society differs from
hunter-gatherer bands of the Paleolithic. One key aspect of
emulations is that they can be checkpointed, backed up, and copied
without errors. This is something which does not exist in biology,
but with which computer users are familiar. Suppose an em is about to
undertake something risky, which might destroy the hardware running
the emulation. It can simply make a backup, store it in a safe place,
and if disaster ensues, arrange to have to the backup restored onto
new hardware, picking up right where it left off at the time of the
backup (but, of course, knowing from others what happened to its
earlier instantiation and acting accordingly). Philosophers will fret
over whether the restored em has the same identity as the one which
was destroyed and whether it has continuity of consciousness. To
this, I say, let them fret; they're always fretting about something.
As an engineer, I don't spend time worrying about things I can't
define, no less observe, such as “consciousness”,
“identity”, or “the soul”. If I did, I'd
worry about whether those things were lost when undergoing general
anaesthesia. Have the wisdom teeth out, wake up, and get on with your
life.
If you have a backup, there's no need to wait until the em from which
it was made is destroyed to launch it. It can be instantiated on
different hardware at any time, and now you have two ems, whose life
experiences were identical up to the time the backup was made, running
simultaneously. This process can be repeated as many times as you
wish, at a cost of only the processing and storage charges to run the
new ems. It will thus be common to capture backups of exceptionally
talented ems at the height of their intellectual and creative powers
so that as many can be created as the market demands their
services. These new instances will require no training, but be able
to undertake new projects within their area of knowledge at the moment
they're launched. Since ems which start out as copies of a common
prototype will be similar, they are likely to understand one another
to an extent even human identical twins do not, and form clans of
those sharing an ancestor. These clans will be composed of subclans
sharing an ancestor which was a member of the clan, but which diverged
from the original prototype before the subclan parent backup was
created.
Because electronic circuits run so much faster than the chemistry of
the brain, ems will have the capability to run over a wide range of
speeds and probably will be able to vary their speed at will. The
faster an em runs, the more it will have to pay for the processing
hardware, electrical power, and cooling resources it requires. The
author introduces a terminology for speed where an em is assumed to
run around the same speed as a human, a kilo-em a thousand times
faster, and a mega-em a million times faster. Ems can also run
slower: a milli-em runs 1000 times slower than a human and a micro-em
at one millionth the speed. This will produce a variation in
subjective time which is entirely novel to the human experience. A
kilo-em will experience a century of subjective time in about a month
of objective time. A mega-em experiences a century of life about
every hour. If the age of em is largely driven by a population which
is kilo-em or faster, it will evolve with a speed so breathtaking as
to be incomprehensible to those who operate on a human time scale. In
objective time, the age of em may only last a couple of years, but to
the ems within it, its history will be as long as the Roman Empire.
What comes next? That's up to the ems; we cannot imagine what they
will accomplish or choose to do in those subjective millennia or millions
of years.
What about humans? The economics of the emergence of an em society
will be interesting. Initially, humans will own everything, but as
the em society takes off and begins to run at least a thousand times
faster than humans, with a population in the trillions, it can be
expected to create wealth at a rate never before experienced. The
economic doubling time of industrial civilisation is about 15 years.
In an em society, the doubling time will be just 18 months and
potentially much faster. In such a situation, the vast majority of
wealth will be within the em world, and humans will be unable to
compete. Humans will essentially be retirees, with their needs and
wants easily funded from the proceeds of their investments in
initially creating the world the ems inhabit. One might worry about
the ems turning upon the humans and choosing to dispense with them
but, as the author notes, industrial societies have not done this with
their own retirees, despite the financial burden of supporting them,
which is far greater than will be the case for ems supporting human
retirees.
The economics of the age of em will be unusual. The fact that an em,
in the prime of life, can be copied at almost no cost will mean that
the supply of labour, even the most skilled and specialised, will be
essentially unlimited. This will drive the compensation for labour
down to near the subsistence level, where subsistence is defined as
the resources needed to run the em. Since it costs no more to create
a copy of a CEO or computer technology research scientist than a
janitor, there will be a great flattening of pay scales, all settling
near subsistence. But since most ems will live mostly in virtual
reality, subsistence need not mean penury: most of their needs and
wants will not be physical, and will cost little or nothing to
provide. Wouldn't it be ironic if the much-feared “robot
revolution” ended up solving the problem of “income
inequality”? Ems may have a limited useful
lifetime to the extent they inherit the human characteristic of the
brain having greatest plasticity in youth and becoming
increasingly fixed in its ways with age, and consequently less able to
innovate and be creative. The author explores how ems may view death
(which for an em means being archived and never re-instantiated) when
there are myriad other copies in existence and new ones being spawned
all the time, and how ems may choose to retire at very low speed and
resource requirements and watch the future play out a thousand times
or faster than a human can.
This is a challenging and often disturbing look at a possible future
which, strange as it may seem, violates no known law of science and
toward which several areas of research are converging today. The book
is simultaneously breathtaking and tedious. The author tries to work
out every aspect of em society: the structure of cities,
economics, law, social structure, love, trust, governance, religion,
customs, and more. Much of this strikes me as highly speculative,
especially since we don't know anything about the actual experience of
living as an em or how we will make the transition from our present
society to one dominated by ems. The author is inordinately fond of
enumerations. Consider this one from chapter 27.
These include beliefs, memories, plans, names, property, cooperation, coalitions, reciprocity, revenge, gifts, socialization, roles, relations, self-control, dominance, submission, norms, morals, status, shame, division of labor, trade, law, governance, war, language, lies, gossip, showing off, signaling loyalty, self-deception, in-group bias, and meta-reasoning.
But for all its strangeness, the book amply rewards the effort you'll invest in reading it. It limns a world as different from our own as any portrayed in science fiction, yet one which is a plausible future that may come to pass in the next century, and is entirely consistent with what we know of science. It raises deep questions of philosophy, what it means to be human, and what kind of future we wish for our species and its successors. No technical knowledge of computer science, neurobiology, nor the origins of intelligence and consciousness is assumed; just a willingness to accept the premise that whatever these things may be, they are independent of the physical substrate upon which they are implemented. - Hawkins, Jeff with Sandra Blakeslee. On Intelligence. New York: Times Books, 2004. ISBN 0-8050-7456-2.
- Ever since the early days of research into the sub-topic of computer science which styles itself “artificial intelligence”, such work has been criticised by philosophers, biologists, and neuroscientists who argue that while symbolic manipulation, database retrieval, and logical computation may be able to mimic, to some limited extent, the behaviour of an intelligent being, in no case does the computer understand the problem it is solving in the sense a human does. John R. Searle's “Chinese Room” thought experiment is one of the best known and extensively debated of these criticisms, but there are many others just as cogent and difficult to refute. These days, criticising artificial intelligence verges on hunting cows with a bazooka—unlike the early days in the 1950s when everybody expected the world chess championship to be held by a computer within five or ten years and mathematicians were fretting over what they'd do with their lives once computers learnt to discover and prove theorems thousands of times faster than they, decades of hype, fads, disappointment, and broken promises have instilled some sense of reality into the expectations most technical people have for “AI”, if not into those working in the field and those they bamboozle with the sixth (or is it the sixteenth) generation of AI bafflegab. AI researchers sometimes defend their field by saying “If it works, it isn't AI”, by which they mean that as soon as a difficult problem once considered within the domain of artificial intelligence—optical character recognition, playing chess at the grandmaster level, recognising faces in a crowd—is solved, it's no longer considered AI but simply another computer application, leaving AI with the remaining unsolved problems. There is certainly some truth in this, but a closer look gives lie to the claim that these problems, solved with enormous effort on the part of numerous researchers, and with the application, in most cases, of computing power undreamed of in the early days of AI, actually represents “intelligence”, or at least what one regards as intelligent behaviour on the part of a living brain. First of all, in no case did a computer “learn” how to solve these problems in the way a human or other organism does; in every case experts analysed the specific problem domain in great detail, developed special-purpose solutions tailored to the problem, and then implemented them on computing hardware which in no way resembles the human brain. Further, each of these “successes” of AI is useless outside its narrow scope of application: a chess-playing computer cannot read handwriting, a speech recognition program cannot identify faces, and a natural language query program cannot solve mathematical “word problems” which pose no difficulty to fourth graders. And while many of these programs are said to be “trained” by presenting them with collections of stimuli and desired responses, no amount of such training will permit, say, an optical character recognition program to learn to write limericks. Such programs can certainly be useful, but nothing other than the fact that they solve problems which were once considered difficult in an age when computers were much slower and had limited memory resources justifies calling them “intelligent”, and outside the marketing department, few people would remotely consider them so. The subject of this ambitious book is not “artificial intelligence” but intelligence: the real thing, as manifested in the higher cognitive processes of the mammalian brain, embodied, by all the evidence, in the neocortex. One of the most fascinating things about the neocortex is how much a creature can do without one, for only mammals have them. Reptiles, birds, amphibians, fish, and even insects (which barely have a brain at all) exhibit complex behaviour, perception of and interaction with their environment, and adaptation to an extent which puts to shame the much-vaunted products of “artificial intelligence”, and yet they all do so without a neocortex at all. In this book, the author hypothesises that the neocortex evolved in mammals as an add-on to the old brain (essentially, what computer architects would call a “bag hanging on the side of the old machine”) which implements a multi-level hierarchical associative memory for patterns and a complementary decoder from patterns to detailed low-level behaviour which, wired through the old brain to the sensory inputs and motor controls, dynamically learns spatial and temporal patterns and uses them to make predictions which are fed back to the lower levels of the hierarchy, which in turns signals whether further inputs confirm or deny them. The ability of the high-level cortex to correctly predict inputs is what we call “understanding” and it is something which no computer program is presently capable of doing in the general case. Much of the recent and present-day work in neuroscience has been devoted to imaging where the brain processes various kinds of information. While fascinating and useful, these investigations may overlook one of the most striking things about the neocortex: that almost every part of it, whether devoted to vision, hearing, touch, speech, or motion appears to have more or less the same structure. This observation, by Vernon B. Mountcastle in 1978, suggests there may be a common cortical algorithm by which all of these seemingly disparate forms of processing are done. Consider: by the time sensory inputs reach the brain, they are all in the form of spikes transmitted by neurons, and all outputs are sent in the same form, regardless of their ultimate effect. Further, evidence of plasticity in the cortex is abundant: in cases of damage, the brain seems to be able to re-wire itself to transfer a function to a different region of the cortex. In a long (70 page) chapter, the author presents a sketchy model of what such a common cortical algorithm might be, and how it may be implemented within the known physiological structure of the cortex. The author is a founder of Palm Computing and Handspring (which was subsequently acquired by Palm). He subsequently founded the Redwood Neuroscience Institute, which has now become part of the Helen Wills Neuroscience Institute at the University of California, Berkeley, and in March of 2005 founded Numenta, Inc. with the goal of developing computer memory systems based on the model of the neocortex presented in this book. Some academic scientists may sniff at the pretensions of a (very successful) entrepreneur diving into their speciality and trying to figure out how the brain works at a high level. But, hey, nobody else seems to be doing it—the computer scientists are hacking away at their monster programs and parallel machines, the brain community seems stuck on functional imaging (like trying to reverse-engineer a microprocessor in the nineteenth century by looking at its gross chemical and electrical properties), and the neuron experts are off dissecting squid: none of these seem likely to lead to an understanding (there's that word again!) of what's actually going on inside their own tenured, taxpayer-funded skulls. There is undoubtedly much that is wrong in the author's speculations, but then he admits that from the outset and, admirably, presents an appendix containing eleven testable predictions, each of which can falsify all or part of his theory. I've long suspected that intelligence has more to do with memory than computation, so I'll confess to being predisposed toward the arguments presented here, but I'd be surprised if any reader didn't find themselves thinking about their own thought processes in a different way after reading this book. You won't find the answers to the mysteries of the brain here, but at least you'll discover many of the questions worth pondering, and perhaps an idea or two worth exploring with the vast computing power at the disposal of individuals today and the boundless resources of data in all forms available on the Internet.
- Hey, Anthony J.G. ed. Feynman and Computation. Boulder, CO: Westview Press, 2002. ISBN 0-8133-4039-X.
- Howard, Michael, David LeBlanc, and John Viega. 19 Deadly Sins of Software Security. Emeryville, CA: Osborne, 2005. ISBN 0-07-226085-8.
- During his brief tenure as director of the National Cyber Security Division of the U.S. Department of Homeland Security, Amit Yoran (who wrote the foreword to this book) got a lot of press attention when he claimed, “Ninety-five percent of software bugs are caused by the same 19 programming flaws.” The list of these 19 dastardly defects was assembled by John Viega who, with his two co-authors, both of whom worked on computer security at Microsoft, attempt to exploit its notoriety in this poorly written, jargon-filled, and utterly worthless volume. Of course, I suppose that's what one should expect when a former official of the agency of geniuses who humiliate millions of U.S. citizens every day to protect them from the peril of grandmothers with exploding sneakers team up with a list of authors that includes a former “security architect for Microsoft's Office division”—why does the phrase “macro virus” immediately come to mind? Even after reading this entire ramble on the painfully obvious, I cannot remotely guess who the intended audience was supposed to be. Software developers who know enough to decode what the acronym-packed (many never or poorly defined) text is trying to say are already aware of the elementary vulnerabilities being discussed and ways to mitigate them. Those without knowledge of competent programming practice are unlikely to figure out what the authors are saying, since their explanations in most cases assume the reader is already aware of the problem. The book is also short (281 pages), generous with white space, and packed with filler: the essential message of what to look out for in code can be summarised in a half-page table: in fact, it has been, on page 262! Not only does every chapter end with a summary of “do” and “don't” recommendations, all of these lists are duplicated in a ten page appendix at the end, presumably added because the original manuscript was too short. Other obvious padding is giving examples of trivial code in a long list of languages (including proprietary trash such as C#, Visual Basic, and the .NET API); around half of the code samples are Microsoft-specific, as are the “Other Resources” at the end of each chapter. My favourite example is on pp. 176–178, which gives sample code showing how to read a password from a file (instead of idiotically embedding it in an application) in four different programming languages: three of them Microsoft-specific. Like many bad computer books, this one seems to assume that programmers can learn only from long enumerations of specific items, as opposed to a theoretical understanding of the common cause which underlies them all. In fact, a total of eight chapters on supposedly different “deadly sins” can be summed up in the following admonition, “never blindly trust any data that comes from outside your complete control”. I had learned this both from my elders and brutal experience in operating system debugging well before my twentieth birthday. Apart from the lack of content and ill-defined audience, the authors write in a dialect of jargon and abbreviations which is probably how morons who work for Microsoft speak to one another: “app”, “libcall”, “proc”, “big-honking”, “admin”, “id” litter the text, and the authors seem to believe the word for a security violation is spelt “breech”. It's rare that I read a technical book in any field from which I learn not a single thing, but that's the case here. Well, I suppose I did learn that a prominent publisher and forty dollar cover price are no guarantee the content of a book will be of any value. Save your money—if you're curious about which 19 “sins” were chosen, just visit the Amazon link above and display the back cover of the book, which contains the complete list.
- Knuth, Donald E. Literate Programming. Stanford: Center for the Study of Language and Information, 1992. ISBN 0-937073-80-6.
- Knuth, Donald E. and Silvio Levy. The CWEB System of Structured Documentation. Reading, MA: Addison-Wesley, 1994. ISBN 0-201-57569-8.
- Kopparapu, Chandra. Load Balancing Servers, Firewalls, and Caches. New York: John Wiley & Sons, 2002. ISBN 0-471-41550-2.
- Don't even think about deploying a server farm or geographically dispersed mirror sites without reading this authoritative book. The Internet has become such a mountain of interconnected kludges that something as conceptually simple as spreading Web and other Internet traffic across a collection of independent servers or sites in the interest of increased performance and fault tolerance becomes a matter of enormous subtlety and hideous complexity. Most of the problems come from the need for “session persistence”: when a new user arrives at your site, you can direct them to any available server based on whatever load balancing algorithm you choose, but if the user's interaction with the server involves dynamically generated content produced by the server (for example, images generated by Earth and Moon Viewer, or items the user places in their shopping cart at a commerce site), subsequent requests by the user must be directed to the same server, as only it contains the state of the user's session. (Some load balancer vendors will try to persuade you that session persistence is a design flaw in your Web applications which you should eliminate by making them stateless or by using a common storage pool shared by all the servers. Don't believe this. I defy you to figure out how an application as simple as Earth and Moon Viewer, which does nothing more complicated than returning a custom Web page which contains a dynamically generated embedded image, can be made stateless. And shared backing store [for example, Network Attached Storage servers] has its own scalability and fault tolerance challenges.) Almost any simple scheme you can come up with to get around the session persistence problem will be torpedoed by one or more of the kludges and hacks through which a user's packet traverses between client and server: NAT, firewalls, proxy servers, content caches, etc. Consider what at first appears to be a foolproof scheme (albeit sub-optimal for load distribution): simply hash the client's IP address into a set of bins, one for each server, and direct the packets accordingly. Certainly, that would work, right? Wrong: huge ISPs such as AOL and EarthLink have farms of proxy servers between their customers and the sites they contact, and these proxy servers are themselves load balanced in a non-persistent manner. So even two TCP connections from the same browser retrieving, say, the text and an image from a single Web page, may arrive at your site apparently originating from different IP addresses! This and dozens of other gotchas and ways to work around them are described in detail in this valuable book, which is entirely vendor-neutral, except for occasionally mentioning products to illustrate different kinds of architectures. It's a lot better to slap your forehead every few pages as you discover something else you didn't think of which will sabotage your best-laid plans than pull your hair out later after putting a clever and costly scheme into production and discovering that it doesn't work. When I started reading this book, I had no idea how I was going to solve the load balancing problem for the Fourmilab site, and now I know precisely how I'm going to proceed. This isn't a book you read for entertainment, but if you need to know this stuff, it's a great place to learn it.
- Kurzweil, Ray. The Singularity Is Near. New York: Viking, 2005. ISBN 0-670-03384-7.
-
What happens if Moore's Law—the annual doubling of computing power
at constant cost—just keeps on going? In this book,
inventor, entrepreneur, and futurist Ray Kurzweil extrapolates the
long-term faster than exponential growth (the exponent is itself
growing exponentially) in computing power to the point where the
computational capacity of the human brain is available for about
US$1000 (around 2020, he estimates), reverse engineering and
emulation of human brain structure permits machine intelligence
indistinguishable from that of humans as defined by the Turing test
(around 2030), and the subsequent (and he believes inevitable)
runaway growth in artificial intelligence leading to a technological
singularity around 2045 when US$1000 will purchase computing power
comparable to that of all presently-existing human brains and the new
intelligence created in that single year will be a billion times
greater than that of the entire intellectual heritage of human
civilisation prior to that date. He argues that the inhabitants of
this brave new world, having transcended biological computation in
favour of nanotechnological substrates “trillions of trillions of
times more capable” will remain human, having preserved their
essential identity and evolutionary heritage across this leap to
Godlike intellectual powers. Then what? One might as well have asked
an ant to speculate on what newly-evolved hominids would end up
accomplishing, as the gap between ourselves and these super cyborgs
(some of the precursors of which the author argues are alive today)
is probably greater than between arthropod and anthropoid.
Throughout this tour de force of boundless
technological optimism, one is impressed by the author's adamantine
intellectual integrity. This is not an advocacy document—in fact,
Kurzweil's view is that the events he envisions are essentially
inevitable given the technological, economic, and moral (curing
disease and alleviating suffering) dynamics driving them.
Potential roadblocks are discussed candidly, along with the
existential risks posed by the genetics, nanotechnology, and robotics
(GNR) revolutions which will set the stage for the singularity. A
chapter is devoted to responding to critics of various aspects of the
argument, in which opposing views are treated with respect.
I'm not going to expound further in great detail. I suspect a majority of
people who read these comments will, in all likelihood, read the book
themselves (if they haven't already) and make up their own minds about it.
If you are at all interested in the evolution of technology in this
century and its consequences for the humans who are creating it, this
is certainly a book you should read. The balance of these remarks
discuss various matters which came to mind as I read the book; they may
not make much sense unless you've read it (You are going to
read it, aren't you?), but may highlight things to reflect upon as you do.
- Switching off the simulation. Page 404 raises a somewhat arcane risk I've pondered at some length. Suppose our entire universe is a simulation run on some super-intelligent being's computer. (What's the purpose of the universe? It's a science fair project!) What should we do to avoid having the simulation turned off, which would be bad? Presumably, the most likely reason to stop the simulation is that it's become boring. Going through a technological singularity, either from the inside or from the outside looking in, certainly doesn't sound boring, so Kurzweil argues that working toward the singularity protects us, if we be simulated, from having our plug pulled. Well, maybe, but suppose the explosion in computing power accessible to the simulated beings (us) at the singularity exceeds that available to run the simulation? (This is plausible, since post-singularity computing rapidly approaches its ultimate physical limits.) Then one imagines some super-kid running top to figure out what's slowing down the First Superbeing Shooter game he's running and killing the CPU hog process. There are also things we can do which might increase the risk of the simulation's being switched off. Consider, as I've proposed, precision fundamental physics experiments aimed at detecting round-off errors in the simulation (manifested, for example, as small violations of conservation laws). Once the beings in the simulation twig to the fact that they're in a simulation and that their reality is no more accurate than double precision floating point, what's the point to letting it run?
- Fifty bits per atom? In the description of the computational capacity of a rock (p. 131), the calculation assumes that 100 bits of memory can be encoded in each atom of a disordered medium. I don't get it; even reliably storing a single bit per atom is difficult to envision. Using the “precise position, spin, and quantum state” of a large ensemble of atoms as mentioned on p. 134 seems highly dubious.
- Luddites. The risk from anti-technology backlash is discussed in some detail. (“Ned Ludd” himself joins in some of the trans-temporal dialogues.) One can imagine the next generation of anti-globalist demonstrators taking to the streets to protest the “evil corporations conspiring to make us all rich and immortal”.
- Fundamentalism. Another risk is posed by fundamentalism, not so much of the religious variety, but rather fundamentalist humanists who perceive the migration of humans to non-biological substrates (at first by augmentation, later by uploading) as repellent to their biological conception of humanity. One is inclined, along with the author, simply to wait until these folks get old enough to need a hip replacement, pacemaker, or cerebral implant to reverse a degenerative disease to motivate them to recalibrate their definition of “purely biological”. Still, I'm far from the first to observe that Singularitarianism (chapter 7) itself has some things in common with religious fundamentalism. In particular, it requires faith in rationality (which, as Karl Popper observed, cannot be rationally justified), and that the intentions of super-intelligent beings, as Godlike in their powers compared to humans as we are to Saccharomyces cerevisiae, will be benign and that they will receive us into eternal life and bliss. Haven't I heard this somewhere before? The main difference is that the Singularitarian doesn't just aspire to Heaven, but to Godhood Itself. One downside of this may be that God gets quite irate.
- Vanity. I usually try to avoid the “Washington read” (picking up a book and flipping immediately to the index to see if I'm in it), but I happened to notice in passing I made this one, for a minor citation in footnote 47 to chapter 2.
- Spindle cells. The material about “spindle cells” on pp. 191–194 is absolutely fascinating. These are very large, deeply and widely interconnected neurons which are found only in humans and a few great apes. Humans have about 80,000 spindle cells, while gorillas have 16,000, bonobos 2,100 and chimpanzees 1,800. If you're intrigued by what makes humans human, this looks like a promising place to start.
- Speculative physics. The author shares my interest in physics verging on the fringe, and, turning the pages of this book, we come across such topics as possible ways to exceed the speed of light, black hole ultimate computers, stable wormholes and closed timelike curves (a.k.a. time machines), baby universes, cold fusion, and more. Now, none of these things is in any way relevant to nor necessary for the advent of the singularity, which requires only well-understood mainstream physics. The speculative topics enter primarily in discussions of the ultimate limits on a post-singularity civilisation and the implications for the destiny of intelligence in the universe. In a way they may distract from the argument, since a reader might be inclined to dismiss the singularity as yet another woolly speculation, which it isn't.
- Source citations. The end notes contain many citations of articles in Wired, which I consider an entertainment medium rather than a reliable source of technological information. There are also references to articles in Wikipedia, where any idiot can modify anything any time they feel like it. I would not consider any information from these sources reliable unless independently verified from more scholarly publications.
- “You apes wanna live forever?” Kurzweil doesn't just anticipate the singularity, he hopes to personally experience it, to which end (p. 211) he ingests “250 supplements (pills) a day and … a half-dozen intravenous therapies each week”. Setting aside the shots, just envision two hundred and fifty pills each and every day! That's 1,750 pills a week or, if you're awake sixteen hours a day, an average of more than 15 pills per waking hour, or one pill about every four minutes (one presumes they are swallowed in batches, not spaced out, which would make for a somewhat odd social life). Between the year 2000 and the estimated arrival of human-level artificial intelligence in 2030, he will swallow in excess of two and a half million pills, which makes one wonder what the probability of choking to death on any individual pill might be. He remarks, “Although my program may seem extreme, it is actually conservative—and optimal (based on my current knowledge).” Well, okay, but I'd worry about a “strategy for preventing heart disease [which] is to adopt ten different heart-disease-prevention therapies that attack each of the known risk factors” running into unanticipated interactions, given how everything in biology tends to connect to everything else. There is little discussion of the alternative approach to immortality with which many nanotechnologists of the mambo chicken persuasion are enamoured, which involves severing the heads of recently deceased individuals and freezing them in liquid nitrogen in sure and certain hope of the resurrection unto eternal life.
- Kurzweil, Ray. The Age of Spiritual Machines. New York: Penguin Books, 1999. ISBN 978-0-14-028202-3.
-
Ray Kurzweil is one of the most vocal advocates of the view
that the exponential growth in computing power (and allied
technologies such as storage capacity and communication bandwidth)
at constant cost which we have experienced for the last half
century, notwithstanding a multitude of well-grounded arguments
that fundamental physical limits on the underlying substrates
will bring it to an end (all of which have proven to be
wrong), will continue for the foreseeable future: in all likelihood
for the entire twenty-first century. Continued exponential
growth in a technology for so long a period is unprecedented in the human experience,
and the consequences as the exponential begins to truly
“kick in” (although an exponential curve is self-similar,
its consequences as perceived by observers whose own criteria for
evaluation are more or less constant will be seen to reach a
“knee” after which they essentially go vertical and
defy prediction). In The Singularity Is Near
(October 2005), Kurzweil argues that once the point is reached
where computers exceed the capability of the human brain and begin
to design their own successors, an almost instantaneous (in terms of
human perception) blow-off will occur, with computers rapidly
converging on the ultimate physical limits on computation, with
capabilities so far beyond those of humans (or even human society
as a whole) that attempting to envision their capabilities or intentions
is as hopeless as a microorganism's trying to master quantum field
theory. You might want to review my notes on 2005's
The Singularity Is Near before reading the
balance of these comments: they provide context as to the extreme
events Kurzweil envisions as occurring in the coming decades, and
there are no “spoilers” for the present book.
When assessing the reliability of predictions, it can be enlightening
to examine earlier forecasts from the same source, especially if
they cover a period of time which has come and gone in the interim.
This book, published in 1999 near the very peak of the
dot-com bubble
provides such an opportunity, and it provides a useful calibration
for the plausibility of Kurzweil's more recent speculations
on the future of computing and humanity. The author's view
of the likely course of the 21st century evolved substantially
between this book and Singularity—in
particular this book envisions no singularity beyond which the
course of events becomes incomprehensible to present-day human
intellects. In the present volume, which employs the curious
literary device of “trans-temporal chat” between
the author, a MOSH (Mostly Original Substrate Human), and a
reader, Molly, who reports from various points in the century
her personal experiences living through it, we encounter
a future which, however foreign, can at least be understood in
terms of our own experience.
This view of the human prospect is very odd indeed, and to this reader more disturbing (verging on creepy) than the approach of a technological singularity. What we encounter here are beings, whether augmented humans or software intelligences with no human ancestry whatsoever, that despite having at hand, by the end of the century, mental capacity per individual on the order of 1024 times that of the human brain (and maybe hundreds of orders of magnitude more if quantum computing pans out), still have identities, motivations, and goals which remain comprehensible to humans today. This seems dubious in the extreme to me, and my impression from Singularity is that the author has rethought this as well.
Starting from the publication date of 1999, the book serves up surveys of the scene in that year, 2009, 2019, 2029, and 2099. The chapter describing the state of computing in 2009 makes many specific predictions. The following are those which the author lists in the “Time Line” on pp. 277–278. Many of the predictions in the main text seem to me to be more ambitious than these, but I shall go with those the author chose as most important for the summary. I have reformatted these as a numbered list to make them easier to cite.- A $1,000 personal computer can perform about a trillion calculations per second.
- Personal computers with high-resolution visual displays come in a range of sizes, from those small enough to be embedded in clothing and jewelry up to the size of a thin book.
- Cables are disappearing. Communication between components uses short-distance wireless technology. High-speed wireless communication provides access to the Web.
- The majority of text is created using continuous speech recognition. Also ubiquitous are language user interfaces (LUIs).
- Most routine business transactions (purchases, travel, reservations) take place between a human and a virtual personality. Often, the virtual personality includes an animated visual presence that looks like a human face.
- Although traditional classroom organization is still common, intelligent courseware has emerged as a common means of learning.
- Pocket-sized reading machines for the blind and visually impaired, “listening machines” (speech-to-text conversion) for the deaf, and computer-controlled orthotic devices for paraplegic individuals result in a growing perception that primary disabilities do not necessarily impart handicaps.
- Translating telephones (speech-to-speech language translation) are commonly used for many language pairs.
- Accelerating returns from the advance of computer technology have resulted in continued economic expansion. Price deflation, which has been a reality in the computer field during the twentieth century, is now occurring outside the computer field. The reason for this is that virtually all economic sectors are deeply affected by the accelerating improvements in the price performance of computing.
- Human musicians routinely jam with cybernetic musicians.
- Bioengineered treatments for cancer and heart disease have greatly reduced the mortality from these diseases.
- The neo-Luddite movement is growing.
This is just so breathtakingly wrong I am at a loss for where to begin, and it was just as completely wrong when the book was published two decades ago as it is today; nothing relevant to these statements has changed. My guess is that Kurzweil was thinking of “intricate mechanisms” within hadrons and mesons, particles made up of quarks and gluons, and not within quarks themselves, which then and now are believed to be point particles with no internal structure whatsoever and are, in any case, impossible to isolate from the particles they compose. When Richard Feynman envisioned molecular nanotechnology in 1959, he based his argument on the well-understood behaviour of atoms known from chemistry and physics, not a leap of faith based on drawing a straight line on a sheet of semi-log graph paper. I doubt one could find a single current practitioner of subatomic physics equally versed in the subject as was Feynman in atomic physics who would argue that engineering at the level of subatomic particles would be remotely feasible. (For atoms, biology provides an existence proof that complex self-replicating systems of atoms are possible. Despite the multitude of environments in the universe since the big bang, there is precisely zero evidence subatomic particles have ever formed structures more complicated than those we observe today.) I will not further belabour the arguments in this vintage book. It is an entertaining read and will certainly expand your horizons as to what is possible and introduce you to visions of the future you almost certainly have never contemplated. But for a view of the future which is simultaneously more ambitious and plausible, I recommend The Singularity Is Near.If engineering at the nanometer scale (nanotechnology) is practical in the year 2032, then engineering at the picometer scale should be practical in about forty years later (because 5.64 = approximately 1,000), or in the year 2072. Engineering at the femtometer (one thousandth of a trillionth of a meter, also referred to as a quadrillionth of a meter) scale should be feasible, therefore, by around the year 2112. Thus I am being a bit conservative to say that femtoengineering is controversial in 2099.
Nanoengineering involves manipulating individual atoms. Picoengineering will involve engineering at the level of subatomic particles (e.g., electrons). Femtoengineering will involve engineering inside a quark. This should not seem particularly startling, as contemporary theories already postulate intricate mechanisms within quarks.
- Kurzweil, Ray. How to Create a Mind. New York: Penguin Books, 2012. ISBN 978-0-14-312404-7.
- We have heard so much about the exponential growth of computing power available at constant cost that we sometimes overlook the fact that this is just one of a number of exponentially compounding technologies which are changing our world at an ever-accelerating pace. Many of these technologies are interrelated: for example, the availability of very fast computers and large storage has contributed to increasingly making biology and medicine information sciences in the era of genomics and proteomics—the cost of sequencing a human genome, since the completion of the Human Genome Project, has fallen faster than the increase of computer power. Among these seemingly inexorably rising curves have been the spatial and temporal resolution of the tools we use to image and understand the structure of the brain. So rapid has been the progress that most of the detailed understanding of the brain dates from the last decade, and new discoveries are arriving at such a rate that the author had to make substantial revisions to the manuscript of this book upon several occasions after it was already submitted for publication. The focus here is primarily upon the neocortex, a part of the brain which exists only in mammals and is identified with “higher level thinking”: learning from experience, logic, planning, and, in humans, language and abstract reasoning. The older brain, which mammals share with other species, is discussed in chapter 5, but in mammals it is difficult to separate entirely from the neocortex, because the latter has “infiltrated” the old brain, wiring itself into its sensory and action components, allowing the neocortex to process information and override responses which are automatic in creatures such as reptiles. Not long ago, it was thought that the brain was a soup of neurons connected in an intricately tangled manner, whose function could not be understood without comprehending the quadrillion connections in the neocortex alone, each with its own weight to promote or inhibit the firing of a neuron. Now, however, it appears, based upon improved technology for observing the structure and operation of the brain, that the fundamental unit in the brain is not the neuron, but a module of around 100 neurons which acts as a pattern recogniser. The internal structure of these modules seems to be wired up from directions from the genome, but the weights of the interconnections within the module are adjusted as the module is trained based upon the inputs presented to it. The individual pattern recognition modules are wired both to pass information on matches to higher level modules, and predictions back down to lower level recognisers. For example, if you've seen the letters “appl” and the next and final letter of the word is a smudge, you'll have no trouble figuring out what the word is. (I'm not suggesting the brain works literally like this, just using this as an example to illustrate hierarchical pattern recognition.) Another important discovery is that the architecture of these pattern recogniser modules is pretty much the same regardless of where they appear in the neocortex, or what function they perform. In a normal brain, there are distinct portions of the neocortex associated with functions such as speech, vision, complex motion sequencing, etc., and yet the physical structure of these regions is nearly identical: only the weights of the connections within the modules and the dyamically-adapted wiring among them differs. This explains how patients recovering from brain damage can re-purpose one part of the neocortex to take over (within limits) for the portion lost. Further, the neocortex is not the rat's nest of random connections we recently thought it to be, but is instead hierarchically structured with a topologically three dimensional “bus” of pre-wired interconnections which can be used to make long-distance links between regions. Now, where this begins to get very interesting is when we contemplate building machines with the capabilities of the human brain. While emulating something at the level of neurons might seem impossibly daunting, if you instead assume the building block of the neocortex is on the order of 300 million more or less identical pattern recognisers wired together at a high level in a regular hierarchical manner, this is something we might be able to think about doing, especially since the brain works almost entirely in parallel, and one thing we've gotten really good at in the last half century is making lots and lots of tiny identical things. The implication of this is that as we continue to delve deeper into the structure of the brain and computing power continues to grow exponentially, there will come a point in the foreseeable future where emulating an entire human neocortex becomes feasible. This will permit building a machine with human-level intelligence without translating the mechanisms of the brain into those comparable to conventional computer programming. The author predicts “this will first take place in 2029 and become routine in the 2030s.” Assuming the present exponential growth curves continue (and I see no technological reason to believe they will not), the 2020s are going to be a very interesting decade. Just as few people imagined five years ago that self-driving cars were possible, while today most major auto manufacturers have projects underway to bring them to market in the near future, in the 2020s we will see the emergence of computational power which is sufficient to “brute force” many problems which were previously considered intractable. Just as search engines and free encyclopedias have augmented our biological minds, allowing us to answer questions which, a decade ago, would have taken days in the library if we even bothered at all, the 300 million pattern recognisers in our biological brains are on the threshold of having access to billions more in the cloud, trained by interactions with billions of humans and, perhaps eventually, many more artificial intelligences. I am not talking here about implanting direct data links into the brain or uploading human brains to other computational substrates although both of these may happen in time. Instead, imagine just being able to ask a question in natural language and get an answer to it based upon a deep understanding of all of human knowledge. If you think this is crazy, reflect upon how exponential growth works or imagine travelling back in time and giving a demo of Google or Wolfram Alpha to yourself in 1990. Ray Kurzweil, after pioneering inventions in music synthesis, optical character recognition, text to speech conversion, and speech recognition, is now a director of engineering at Google. In the Kindle edition, the index cites page numbers in the print edition to which the reader can turn since the electronic edition includes real page numbers. Index items are not, however, directly linked to the text cited.
- Lanier, Jaron. You Are Not a Gadget. New York: Alfred A. Knopf, 2010. ISBN 978-0-307-26964-5.
- In The Fatal Conceit (March 2005) Friedrich A. Hayek observed that almost any noun in the English language is devalued by preceding it with “social”. In this book, virtual reality pioneer, musician, and visionary Jaron Lanier argues that the digital revolution, which began in the 1970s with the advent of the personal computer and became a new foundation for human communication and interaction with widespread access to the Internet and the Web in the 1990s, took a disastrous wrong turn in the early years of the 21st century with the advent of the so-called “Web 2.0” technologies and “social networking”—hey, Hayek could've told you! Like many technologists, the author was optimistic that with the efflorescence of the ubiquitous Internet in the 1990s combined with readily-affordable computer power which permitted photorealistic graphics and high fidelity sound synthesis, a new burst of bottom-up creativity would be unleashed; creative individuals would be empowered to realise not just new art, but new forms of art, along with new ways to collaborate and distribute their work to a global audience. This Army of Davids (March 2006) world, however, seems to have been derailed or at least delayed, and instead we've come to inhabit an Internet and network culture which is darker and less innovative. Lanier argues that the phenomenon of technological “lock in” makes this particularly ominous, since regrettable design decisions whose drawbacks were not even perceived when they were made, tend to become entrenched and almost impossible to remedy once they are widely adopted. (For example, just look at the difficulties in migrating the Internet to IPv6.) With application layer protocols, fundamentally changing them becomes almost impossible once a multitude of independently maintained applications rely upon them to intercommunicate. Consider MIDI, which the author uses as an example of lock-in. Originally designed to allow music synthesisers and keyboards to interoperate, it embodies a keyboardist's view of the concept of a note, which is quite different from that, say, of a violinist or trombone player. Even with facilities such as pitch bend, there are musical articulations played on physical instruments which cannot be represented in MIDI sequences. But since MIDI has become locked in as the lingua franca of electronic music production, in effect the musical vocabulary has been limited to those concepts which can be represented in MIDI, resulting in a digital world which is impoverished in potential compared to the analogue instruments it aimed to replace. With the advent of “social networking”, we appear to be locking in a representation of human beings as database entries with fields chosen from a limited menu of choices, and hence, as with MIDI, flattening down the unbounded diversity and potential of human individuals to categories which, not coincidentally, resemble the demographic bins used by marketers to target groups of customers. Further, the Internet, through its embrace of anonymity and throwaway identities and consequent devaluing of reputation, encourages mob behaviour and “drive by” attacks on individuals which make many venues open to the public more like a slum than an affinity group of like-minded people. Lanier argues that many of the pathologies we observe in behaviour on the Internet are neither inherent nor inevitable, but rather the consequences of bad user interface design. But with applications built on social networking platforms proliferating as rapidly as me-too venture capital hoses money in their direction, we may be stuck with these regrettable decisions and their pernicious consequences for a long time to come. Next, the focus turns to the cult of free and open source software, “cloud computing”, “crowd sourcing”, and the assumption that a “hive mind” assembled from a multitude of individuals collaborating by means of the Internet can create novel and valuable work and even assume some of the attributes of personhood. Now, this may seem absurd, but there are many people in the Silicon Valley culture to whom these are articles of faith, and since these people are engaged in designing the tools many of us will end up using, it's worth looking at the assumptions which inform their designs. Compared to what seemed the unbounded potential of the personal computer and Internet revolutions in their early days, what the open model of development has achieved to date seems depressingly modest: re-implementations of an operating system, text editor, and programming language all rooted in the 1970s, and creation of a new encyclopedia which is structured in the same manner as paper encyclopedias dating from a century ago—oh wow. Where are the immersive massively multi-user virtual reality worlds, or the innovative presentation of science and mathematics in an interactive exploratory learning environment, or new ways to build computer tools without writing code, or any one of the hundreds of breakthroughs we assumed would come along when individual creativity was unleashed by their hardware prerequisites becoming available to a mass market at an affordable price? Not only have the achievements of the free and open movement been, shall we say, modest, the other side of the “information wants to be free” creed has devastated traditional content providers such as the music publishing, newspaper, and magazine businesses. Now among many people there's no love lost for the legacy players in these sectors, and a sentiment of “good riddance” is common, if not outright gloating over their demise. But what hasn't happened, at least so far, is the expected replacement of these physical delivery channels with electronic equivalents which generate sufficient revenue to allow artists, journalists, and other primary content creators to make a living as they did before. Now, certainly, these occupations are a meritocracy where only a few manage to support themselves, no less become wealthy, while far more never make it. But with the mass Internet now approaching its twentieth birthday, wouldn't you expect at least a few people to have figured out how to make it work for them and prospered as creators in this new environment? If so, where are they? For that matter, what new musical styles, forms of artistic expression, or literary genres have emerged in the age of the Internet? Has the lack of a viable business model for such creations led to a situation the author describes as, “It's as if culture froze just before it became digitally open, and all we can do now is mine the past like salvagers picking over a garbage dump.” One need only visit YouTube to see what he's talking about. Don't read the comments there—that path leads to despair, which is a low state. Lanier's interests are eclectic, and a great many matters are discussed here including artificial intelligence, machine language translation, the financial crisis, zombies, neoteny in humans and human cultures, and cephalopod envy. Much of this is fascinating, and some is irritating, such as the discussion of the recent financial meltdown where it becomes clear the author simply doesn't know what he's talking about and misdiagnoses the causes of the catastrophe, which are explained so clearly in Thomas Sowell's The Housing Boom and Bust (March 2010). I believe this is the octopus video cited in chapter 14. The author was dubious, upon viewing this, that it wasn't a computer graphics trick. I have not, as he has, dived the briny deep to meet cephalopods on their own turf, and I remain sceptical that the video represents what it purports to. This is one of the problems of the digital media age: when anything you can imagine can be persuasively computer synthesised, how can you trust any reportage of a remarkable phenomenon to be genuine if you haven't observed it for yourself? Occasional aggravations aside, this is a thoughtful exploration of the state of the technologies which are redefining how people work, play, create, and communicate. Readers frustrated by the limitations and lack of imagination which characterises present-day software and network resources will discover, in reading this book, that tremendously empowering phrase, “it doesn't have to be that way”, and perhaps demand better of those bringing products to the market or perhaps embark upon building better tools themselves.
- Lundstrom, David E. A Few Good Men from Univac. Cambridge, MA: MIT Press, 1987. ISBN 0-262-12120-4.
- The author joined UNIVAC in 1955 and led the testing of the UNIVAC II which, unlike the UNIVAC I, was manufactured in the St. Paul area. (This book uses “Univac” as the name of the company and its computers; in my experience and in all the documents in my collection, the name, originally an acronym for “UNIVersal Automatic Computer”, was always written in all capitals: “UNIVAC”; that is the convention I shall use here.) He then worked on the development of the Navy Tactical Data System (NTDS) shipboard computer, which was later commercialised as the UNIVAC 490 real-time computer. The UNIVAC 1107 also used the NTDS circuit design and I/O architecture. In 1963, like many UNIVAC alumni, Lundstrom crossed the river to join Control Data, where he worked until retiring in 1985. At Control Data he was responsible for peripherals, terminals, and airline reservation system development. It was predictable but sad to observe how Control Data, founded by a group of talented innovators to escape the stifling self-destructive incompetence of UNIVAC management, rapidly built up its own political hierarchy which chased away its own best people, including Seymour Cray. It's as if at a board meeting somebody said, “Hey, we're successful now! Let's build a big office tower and fill it up with idiots and politicians to keep the technical geniuses from getting anything done.” Lundstrom provides an authentic view from the inside of the mainframe computer business over a large part of its history. His observations about why technology transfer usually fails and the destruction wreaked on morale by incessant reorganisations and management shifts in direction are worth pondering. Lundstrom's background is in hardware. In chapter 13, before describing software, he cautions that “Professional programmers are going to disagree violently with what I say.” Well, this professional programmer certainly did, but it's because most of what he goes on to say is simply wrong. But that's a small wart on an excellent, insightful, and thoroughly enjoyable book. This book is out of print; used copies are generally available but tend to be expensive—you might want to keep checking over a period of months as occasionally a bargain will come around.
- Marasco, Joe. The Software Development Edge. Upper Saddle River, NJ: Addison-Wesley, 2005. ISBN 0-321-32131-6.
- I read this book in manuscript form when it was provisionally titled The Psychology of Software Development.
- McConnell, Brian. Beyond Contact: A Guide to SETI and Communicating with Alien Civilizations. Sebastopol, CA: O'Reilly, 2001. ISBN 0-596-00037-5.
- Miranda, Eduardo Reck. Composing Music with Computers. Oxford: Focal Press, 2001. ISBN 0-240-51567-6.
- Post, David G. In Search of Jefferson's Moose. New York: Oxford University Press, 2009. ISBN 978-0-19-534289-5.
- In 1787, while serving as Minister to France, Thomas Jefferson took time out from his diplomatic duties to arrange to have shipped from New Hampshire across the Atlantic Ocean the complete skeleton, skin, and antlers of a bull moose, which was displayed in his residence in Paris. Jefferson was involved in a dispute with the Comte de Buffon, who argued that the fauna of the New World were degenerate compared to those of Europe and Asia. Jefferson concluded that no verbal argument or scientific evidence would be as convincing of the “structure and majesty of American quadrupeds” as seeing a moose in the flesh (or at least the bone), so he ordered one up for display. Jefferson was a passionate believer in the exceptionality of the New World and the prospects for building a self-governing republic in its expansive territory. If it took hauling a moose all the way to Paris to convince Europeans disdainful of the promise of his nascent nation, then so be it—bring on the moose! Among Jefferson's voluminous writings, perhaps none expressed these beliefs as strongly as his magisterial Notes on the State of Virginia. The present book, subtitled “Notes on the State of Cyberspace” takes Jefferson's work as a model and explores this new virtual place which has been built based upon a technology which simply sends packets of data from place to place around the world. The parallels between the largely unexplored North American continent of Jefferson's time and today's Internet are strong and striking, as the author illustrates with extensive quotations from Jefferson interleaved in the text (set in italics to distinguish them from the author's own words) which are as applicable to the Internet today as the land west of the Alleghenies in the late 18th century. Jefferson believed in building systems which could scale to arbitrary size without either losing their essential nature or becoming vulnerable to centralisation and the attendant loss of liberty and autonomy. And he believed that free individuals, living within such a system and with access to as much information as possible and the freedom to communicate without restrictions would self-organise to perpetuate, defend, and extend such a polity. While Europeans, notably Montesquieu, believed that self-governance was impossible in a society any larger than a city-state, and organised their national and imperial governments accordingly, Jefferson's 1784 plan for the government of new Western territory set forth an explicitly power law fractal architecture which, he believed, could scale arbitrarily large without depriving citizens of local control of matters which directly concerned them. This architecture is stunningly similar to that of the global Internet, and the bottom-up governance of the Internet to date (which Post explores in some detail) is about as Jeffersonian as one can imagine. As the Internet has become a central part of global commerce and the flow of information in all forms, the eternal conflict between the decentralisers and champions of individual liberty (with confidence that free people will sort things out for themselves)—the Jeffersonians—and those who believe that only strong central authority and the vigorous enforcement of rules can prevent chaos—Hamiltonians—has emerged once again in the contemporary debate about “Internet governance”. This is a work of analysis, not advocacy. The author, a law professor and regular contributor to The Volokh Conspiracy Web log, observes that, despite being initially funded by the U.S. Department of Defense, the development of the Internet to date has been one of the most Jeffersonian processes in history, and has scaled from a handful of computers in 1969 to a global network with billions of users and a multitude of applications never imagined by its creators, and all through consensual decision making and contractual governance with nary a sovereign gun-wielder in sight. So perhaps before we look to “fix” the unquestioned problems and challenges of the Internet by turning the Hamiltonians loose upon it, we should listen well to the wisdom of Jefferson, who has much to say which is directly applicable to exploring, settling, and governing this new territory which technology has opened up. This book is a superb way to imbibe the wisdom of Jefferson, while learning the basics of the Internet architecture and how it, in many ways, parallels that of aspects of Jefferson's time. Jefferson even spoke to intellectual property issues which read like today's news, railing against a “rascal” using an abusive patent of a long-existing device to extort money from mill owners (p. 197), and creating and distributing “freeware” including a design for a uniquely efficient plough blade based upon Newton's Principia which he placed in the public domain, having “never thought of monopolizing by patent any useful idea which happened to offer itself to me” (p. 196). So astonishing was Jefferson's intellect that as you read this book you'll discover that he has a great deal to say about this new frontier we're opening up today. Good grief—did you know that the Oxford English Dictionary even credits Jefferson with being the first person to use the words “authentication” and “indecipherable” (p. 124)? The author's lucid explanations, deft turns of phrase, and agile leaps between the eighteenth and twenty-first centuries are worthy of the forbidding standard set by the man so extensively quoted here. Law professors do love their footnotes, and this is almost two books in one: the focused main text and the more rambling but fascinating footnotes, some of which span several pages. There is also an extensive list of references and sources for all of the Jefferson quotations in the end notes.
- Purdy, Gregor N. Linux iptables Pocket Reference. Sebastopol, CA: O'Reilly, 2004. ISBN 0-596-00569-5.
-
Sure, you could just read the manual pages, but when your
site is under attack and you're the “first responder”, this little
book is just what you want in your sweaty fingers. It's also a handy
reference to the fields in IP, TCP, UDP, and ICMP packets, which can
be useful in interpreting packet dumps. Although intended as a
reference, it's well worth taking the time (less than an hour) to
read cover to cover. There are a number of very nice
facilities in iptables/Netfilter which permit responding to
common attacks. For example, the iplimit match allows
blocking traffic from the bozone layer (yes, you—I know who
you are and I know where you live) which ties up all of your HTTP
server processes by connecting to them and then letting them time out or,
slightly more sophisticated, feeding characters of a request every
20 seconds or so to keep it alive. The solution is:
/sbin/iptables -A INPUT -p tcp --syn --dport 80 -m iplimit \ --iplimit-above 20 --iplimit-mask 32 -j REJECTAnybody who tries to open more than 20 connections will get whacked on each additional SYN packet. You can see whether this rule is affecting too many legitimate connections with the status query:/sbin/iptables -L -vGeekly reading, to be sure, but just the thing if you're responsible for defending an Internet server or site from malefactors in the Internet Slum. - Ray, Erik T. and Jason McIntosh. Perl and XML. Sebastopol, CA: O'Reilly, 2002. ISBN 0-596-00205-X.
- Reynolds, Glenn. An Army of Davids. Nashville: Nelson Current, 2006. ISBN 1-59555-054-2.
- In this book, law professor and über blogger (InstaPundit.com) Glenn Reynolds explores how present and near-future technology is empowering individuals at the comparative expense of large organisations in fields as diverse as retailing, music and motion picture production, national security, news gathering, opinion journalism, and, looking further out, nanotechnology and desktop manufacturing, human longevity and augmentation, and space exploration and development (including Project Orion [pp. 228–233]—now there's a garage start-up I'd love to work on!). Individual empowerment is, like the technology which creates it, morally neutral: good people can do more good, and bad people can wreak more havoc. Reynolds is relentlessly optimistic, and I believe justifiably so; good people outnumber bad people by a large majority, and in a society which encourages them to be “a pack, not a herd” (the title of chapter 5), they will have the means in their hands to act as a societal immune system against hyper-empowered malefactors far more effective than heavy-handed top-down repression and fear-motivated technological relinquishment. Anybody who's seeking “the next big thing” couldn't find a better place to start than this book. Chapters 2, 3 and 7, taken together, provide a roadmap for the devolution of work from downtown office towers to individual entrepreneurs working at home and in whatever environments attract them, and the emergence of “horizontal knowledge”, supplanting the top-down one-to-many model of the legacy media. There are probably a dozen ideas for start-ups with the potential of eBay and Amazon lurking in these chapters if you read them with the right kind of eyes. If the business and social model of the twenty-first century indeed comes to resemble that of the eighteenth, all of those self-reliant independent people are going to need lots of products and services they will find indispensable just as soon as somebody manages to think of them. Discovering and meeting these needs will pay well. The “every person an entrepreneur” world sketched here raises the same concerns I expressed in regard to David Bolchover's The Living Dead (January 2006): this will be a wonderful world, indeed, for the intelligent and self-motivated people who will prosper once liberated from corporate cubicle indenture. But not everybody is like that: in particular, those people tend to be found on the right side of the bell curve, and for every one on the right, there's one equally far to the left. We have already made entire categories of employment for individuals with average or below-average intelligence redundant. In the eighteenth century, there were many ways in which such people could lead productive and fulfilling lives; what will they do in the twenty-first? Further, ever since Bismarck, government schools have been manufacturing worker-bees with little initiative, and essentially no concept of personal autonomy. As I write this, the élite of French youth is rioting over a proposal to remove what amounts to a guarantee of lifetime employment in a first job. How will people so thoroughly indoctrinated in collectivism fare in an individualist renaissance? As a law professor, the author spends much of his professional life in the company of high-intelligence, strongly-motivated students, many of whom contemplate an entrepreneurial career and in any case expect to be judged on their merits in a fiercely competitive environment. One wonders if his optimism might be tempered were he to spend comparable time with denizens of, say, the school of education. But the fact that there will be problems in the future shouldn't make us fear it—heaven knows there are problems enough in the present, and the last century was kind of a colossal monument to disaster and tragedy; whatever the future holds, the prescription of more freedom, more information, greater wealth and health, and less coercion presented here is certain to make it a better place to live. The individualist future envisioned here has much in common with that foreseen in the 1970s by Timothy Leary, who coined the acronym “SMIILE” for “Space Migration, Intelligence Increase, Life Extension”. The “II” is alluded to in chapter 12 as part of the merging of human and machine intelligence in the singularity, but mightn't it make sense, as Leary advocated, to supplement longevity research with investigation of the nature of human intelligence and near-term means to increase it? Realising the promise and avoiding the risks of the demanding technologies of the future are going to require both intelligence and wisdom; shifting the entire bell curve to the right, combined with the wisdom of longer lives may be key in achieving the much to be desired future foreseen here. InstaPundit visitors will be familiar with the writing style, which consists of relatively brief discussion of a multitude of topics, each with one or more references for those who wish to “read the whole thing” in more depth. One drawback of the print medium is that although many of these citations are Web pages, to get there you have to type in lengthy URLs for each one. An on-line edition of the end notes with all the on-line references as clickable links would be a great service to readers.
- Rucker, Rudy. The Lifebox, the Seashell, and the Soul. New York: Thunder's Mouth Press, 2005. ISBN 1-56025-722-9.
- I read this book in manuscript form. An online excerpt is available.
- Schildt, Herbert. STL Programming from the Ground Up. Berkeley: Osborne, 1999. ISBN 0-07-882507-5.
- Schmitt, Christopher. CSS Cookbook. Sebastopol, CA: O'Reilly, 2004. ISBN 0-596-00576-8.
- It's taken a while, but Cascading Style Sheets have finally begun to live up to their promise of separating content from presentation on the Web, allowing a consistent design, specified in a single place and easily modified, to be applied to large collections of documents, and permitting content to be rendered in different ways depending on the media and audience: one style for online reading, another for printed output, an austere presentation for handheld devices, large type for readers with impaired vision, and a text-only format tailored for screen reader programs used by the blind. This book provides an overview of CSS solutions for common Web design problems, with sample code and screen shots illustrating what can be accomplished. It doesn't purport to be a comprehensive reference—you'll want to have Eric Meyer's Cascading Style Sheets: The Definitive Guide at hand as you develop your own CSS solutions, but Schmitt's book is valuable in showing how common problems can be solved in ways which aren't obvious from reading the specification or a reference book. Particularly useful for the real-world Web designer are Schmitt's discussion of which CSS features work and don't work in various popular browsers and suggestions of work-arounds to maximise the cross-platform portability of pages. Many of the examples in this book are more or less obvious, and embody techniques which folks who've rolled their own Movable Type style sheets will be familiar, but every chapter has one or more gems which caused this designer of minimalist Web pages to slap his forehead and exclaim, “I didn't know you could do that!” Chapter 9, which presents a collection of brutal hacks, many involving exploiting parsing bugs, for working around browser incompatibilities may induce nausea in those who cherish standards compliance or worry about the consequences of millions of pages on the Web containing ticking time bombs which will cause them to fall flat on their faces when various browser bugs are fixed. One glimpses here the business model of the Web site designer who gets paid when the customer is happy with how the site looks in Exploder and views remediation of incompatibilities down the road as a source of recurring revenue. Still, if you develop and maintain Web sites at the HTML level, there are many ideas here which can lead to more effective Web pages, and encourage you to dig deeper into the details of CSS.
- Schneider, Ben Ross, Jr. Travels in Computerland. Reading, MA: Addison-Wesley, 1974. ISBN 0-201-06737-4.
- It's been almost thirty years since I first read this delightful little book, which is now sadly out of print. It's well worth the effort of tracking down a used copy. You can generally find one in readable condition for a reasonable price through the link above or through abebooks.com. If you're too young to have experienced the mainframe computer era, here's an illuminating and entertaining view of just how difficult it was to accomplish anything back then; for those of us who endured the iron age of computing, it is a superb antidote to nostalgia. The insights into organising and managing a decentralised, multidisciplinary project under budget and deadline constraints in an era of technological change are as valid today as they were in the 1970s. The glimpse of the embryonic Internet on pages 241–242 is a gem.
- Spufford, Francis. Backroom Boys: The Secret Return of the British Boffin. London: Faber and Faber, 2003. ISBN 0-571-21496-7.
- It is rare to encounter a book about technology and technologists which even attempts to delve into the messy real-world arena where science, engineering, entrepreneurship, finance, marketing, and government policy intersect, yet it is there, not solely in the technological domain, that the roots of both great successes and calamitous failures lie. Backroom Boys does just this and pulls it off splendidly, covering projects as disparate as the Black Arrow rocket, Concorde, mid 1980s computer games, mobile telephony, and sequencing the human genome. The discussion on pages 99 and 100 of the dynamics of new product development in the software business is as clear and concise a statement I've seen of the philosophy that's guided my own activities for the past 25 years. While celebrating the technological renaissance of post-industrial Britain, the author retains the characteristic British intellectual's disdain for private enterprise and economic liberty. In chapter 4, he describes Vodaphone's development of the mobile phone market: “It produced a blind, unplanned, self-interested search strategy, capitalism's classic method for exploring a new space in the market where profit may be found.” Well…yes…indeed, but that isn't just “capitalism's” classic method, but the very one employed with great success by life on Earth lo these four and a half billion years (see The Genius Within, April 2003). The wheels fall off in chapter 5. Whatever your position may have been in the battle between Celera and the public Human Genome Project, Spufford's collectivist bias and ignorance of economics (simply correcting the noncontroversial errors in basic economics in this chapter would require more pages than it fills) gets in the way of telling the story of how the human genome came to be sequenced five years before the original estimated date. A truly repugnant passage on page 173 describes “how science should be done”. Taxpayer-funded researchers, a fine summer evening, “floated back downstream carousing, with stubs of candle stuck to the prows, … and the voices calling to and fro across the water as the punts drifted home under the overhanging trees in the green, green, night.“ Back to the taxpayer-funded lab early next morning, to be sure, collecting their taxpayer-funded salaries doing the work they love to advance their careers. Nary a word here of the cab drivers, sales clerks, construction workers and, yes, managers of biotech start-ups, all taxed to fund this scientific utopia, who lack the money and free time to pass their own summer evenings so sublimely. And on the previous page, the number of cells in the adult body of C. elegans is twice given as 550. Gimme a break—everybody knows there are 959 somatic cells in the adult hermaphrodite, 1031 in the male; he's confusing adults with 558-cell newly-hatched L1 larvæ.
- Standage, Tom. The Victorian Internet. New York: Berkley, 1998. ISBN 0-425-17169-8.
- Stephenson, Neal. Cryptonomicon. New York: Perennial, 1999. ISBN 0-380-78862-4.
-
I've found that I rarely enjoy, and consequently am disinclined
to pick up, these huge, fat, square works of fiction cranked
out by contemporary super scribblers such as Tom Clancy,
Stephen King, and J.K. Rowling. In each case, the author
started out and made their name crafting intricately
constructed, tightly plotted page-turners, but later on
succumbed to a kind of mid-career spread which yields
flabby doorstop novels that give you hand cramps if you
read them in bed and contain more filler than thriller.
My hypothesis is that when a talented author is getting
started, their initial books receive the close attention of
a professional editor and benefit from the discipline
imposed by an individual whose job is to flense the flab
from a manuscript. But when an author becomes highly
successful—a “property” who can be relied
upon to crank out best-seller after best-seller, it becomes
harder for an editor to restrain an author's proclivity to
bloat and bloviation. (This is not to say that all authors
are so prone, but some certainly are.) I mean, how would
you feel giving Tom Clancy advice on the art
of crafting thrillers, even though
Executive Orders
could easily have been cut by a third and would probably
have been a better novel at half the size.
This is why, despite my having tremendously enjoyed his
earlier
Snow Crash
and
The Diamond Age,
Neal Stephenson's Cryptonomicon sat on
my shelf for almost four years before I decided to
take it with me on a trip and give it a try. Hey,
even later Tom Clancy can be enjoyed as “airplane”
books as long as they fit in your carry-on bag! While ageing
on the shelf, this book was one of the most frequently
recommended by visitors
to this page, and friends to whom I mentioned my hesitation to dive
into the book unanimously said, “You really ought to read
it.” Well, I've finished it, so now I'm in a position to tell
you, “You really ought to read it.” This is simply
one of the best modern novels I have read in years.
The book is thick, but that's because the story is deep and sprawling
and requires a large canvas. Stretching over six decades and three
generations, and melding genera as disparate as military history,
cryptography, mathematics and computing, business and economics,
international finance, privacy and individualism versus the snooper
state and intrusive taxation, personal eccentricity and humour,
telecommunications policy and technology, civil and military engineering,
computers and programming, the hacker and cypherpunk culture,
and personal empowerment as a way of avoiding repetition of the tragedies of the
twentieth century, the story defies classification into any
neat category. It is not science fiction, because all of the
technologies exist (or plausibly could have existed—well,
maybe not the
Galvanick Lucipher
[p. 234; all page
citations are to the trade paperback edition linked above. I'd
usually cite by chapter, but they aren't numbered and there is
no table of contents]—in the epoch in which they appear).
Some call it a “techno thriller”, but it isn't really
a compelling page-turner in that sense; this is a book you want
to savour over a period of time, watching the story
lines evolve and weave together over the decades, and thinking
about the ideas which underlie the plot line.
The breadth of the topics which figure in this story requires
encyclopedic knowledge. which the author demonstrates while
making it look effortless, never like he's showing off. Stephenson
writes with the kind of universal expertise for which Isaac Asimov was
famed, but he's a better writer than the Good Doctor,
and that's saying something. Every few pages you come across a
gem such as the following (p. 207), which is the funniest
paragraph I've read in many a year.
He was born Graf Heinrich Karl Wilhelm Otto Friedrich von Übersetzenseehafenstadt, but changed his name to Nigel St. John Gloamthorpby, a.k.a. Lord Woadmire, in 1914. In his photograph, he looks every inch a von Übersetzenseehafenstadt, and he is free of the cranial geometry problem so evident in the older portraits. Lord Woadmire is not related to the original ducal line of Qwghlm, the Moore family (Anglicized from the Qwghlmian clan name Mnyhrrgh) which had been terminated in 1888 by a spectacularly improbable combination of schistosomiasis, suicide, long-festering Crimean war wounds, ball lightning, flawed cannon, falls from horses, improperly canned oysters, and rogue waves.
On p. 352 we find one of the most lucid and concise explanations I've ever read of why it far more difficult to escape the grasp of now-obsolete technologies than most technologists may wish.(This is simply because the old technology is universally understood by those who need to understand it, and it works well, and all kinds of electronic and software technology has been built and tested to work within that framework, and why mess with success, especially when your profit margins are so small that they can only be detected by using techniques from quantum mechanics, and any glitches vis-à-vis compatibility with old stuff will send your company straight into the toilet.)
In two sentences on p. 564, he lays out the essentials of the original concept for Autodesk, which I failed to convey (providentially, in retrospect) to almost every venture capitalist in Silicon Valley in thousands more words and endless, tedious meetings.“ … But whenever a business plan first makes contact with the actual market—the real world—suddenly all kinds of stuff becomes clear. You may have envisioned half a dozen potential markets for your product, but as soon as you open your doors, one just explodes from the pack and becomes so instantly important that good business sense dictates that you abandon the others and concentrate all your efforts.”
And how many New York Times Best-Sellers contain working source code (p, 480) for a Perl program? A 1168 page mass market paperback edition is now available, but given the unwieldiness of such an edition, how much you're likely to thumb through it to refresh your memory on little details as you read it, the likelihood you'll end up reading it more than once, and the relatively small difference in price, the trade paperback cited at the top may be the better buy. Readers interested in the cryptographic technology and culture which figure in the book will find additional information in the author's Cryptonomicon cypher-FAQ. - Tegmark, Max. Life 3.0. New York: Alfred A. Knopf, 2017. ISBN 978-1-101-94659-6.
-
The Earth formed from the protoplanetary disc surrounding the
young Sun around 4.6 billion years ago. Around one hundred
million years later, the nascent planet, beginning to solidify,
was clobbered by a giant impactor which ejected the mass that
made the Moon. This impact completely re-liquefied the Earth and
Moon. Around 4.4 billion years ago, liquid water appeared on
the Earth's surface (evidence for this comes from
Hadean
zircons which date from this era).
And, some time thereafter, just about as soon as the Earth
became environmentally hospitable to life (lack of disruption
due to bombardment by comets and asteroids, and a temperature
range in which the chemical reactions of life can proceed),
life appeared. In speaking of the origin of life, the evidence
is subtle and it's hard to be precise. There is completely
unambiguous evidence of life on Earth 3.8 billion years ago, and
more subtle clues that life may have existed as early as 4.28
billion years before the present. In any case, the Earth has
been home to life for most of its existence as a planet.
This was what the author calls “Life 1.0”. Initially
composed of single-celled organisms (which, nonetheless, dwarf
in complexity of internal structure and chemistry anything
produced by other natural processes or human technology to this
day), life slowly diversified and organised into colonies of
identical cells, evidence for which can be seen in
rocks
today.
About half a billion years ago, taking advantage of the far more
efficient metabolism permitted by the oxygen-rich atmosphere
produced by the simple organisms which preceded them, complex
multi-cellular creatures sprang into existence in the
“Cambrian
explosion”. These critters manifested all
the body forms found today, and every living being traces
its lineage back to them. But they were still Life 1.0.
What is Life 1.0? Its key characteristics are that it can
metabolise and reproduce, but that it can learn only
through evolution. Life 1.0, from bacteria through insects,
exhibits behaviour which can be quite complex, but that
behaviour can be altered only by the random variation of
mutations in the genetic code and natural selection of
those variants which survive best in their environment. This
process is necessarily slow, but given the vast expanses of
geological time, has sufficed to produce myriad species,
all exquisitely adapted to their ecological niches.
To put this in present-day computer jargon, Life 1.0 is
“hard-wired”: its hardware (body plan and metabolic
pathways) and software (behaviour in response to stimuli) are
completely determined by its genetic code, and can be altered
only through the process of evolution. Nothing an organism
experiences or does can change its genetic programming: the
programming of its descendants depends solely upon its success
or lack thereof in producing viable offspring and the luck of
mutation and recombination in altering the genome they inherit.
Much more recently, Life 2.0 developed. When? If you want
to set a bunch of paleontologists squabbling, simply ask them
when learned behaviour first appeared, but some time between
the appearance of the first mammals and the ancestors of
humans, beings developed the ability to learn from
experience and alter their behaviour accordingly. Although
some would argue simpler creatures (particularly
birds)
may do this, the fundamental hardware which seems to enable
learning is the
neocortex,
which only mammalian brains possess. Modern humans are the
quintessential exemplars of Life 2.0; they not only learn from
experience, they've figured out how to pass what they've learned
to other humans via speech, writing, and more recently, YouTube
comments.
While Life 1.0 has hard-wired hardware and software, Life 2.0 is
able to alter its own software. This is done by training the
brain to respond in novel ways to stimuli. For example, you're
born knowing no human language. In childhood, your brain
automatically acquires the language(s) you hear from those
around you. In adulthood you may, for example, choose to learn
a new language by (tediously) training your brain to understand,
speak, read, and write that language. You have deliberately
altered your own software by reprogramming your brain, just as
you can cause your mobile phone to behave in new ways by
downloading a new application. But your ability to change
yourself is limited to software. You have to work with the
neurons and structure of your brain. You might wish to have
more or better memory, the ability to see more colours (as some
insects do), or run a sprint as fast as the current Olympic
champion, but there is nothing you can do to alter those
biological (hardware) constraints other than hope, over many
generations, that your descendants might evolve those
capabilities. Life 2.0 can design (within limits) its software,
but not its hardware.
The emergence of a new major revision of life is a big
thing. In 4.5 billion years, it has only happened twice,
and each time it has remade the Earth. Many technologists
believe that some time in the next century (and possibly
within the lives of many reading this review) we may see
the emergence of Life 3.0. Life 3.0, or Artificial
General Intelligence (AGI), is machine intelligence,
on whatever technological substrate, which can perform
as well as or better than human beings, all of the
intellectual tasks which they can do. A Life 3.0 AGI
will be better at driving cars, doing scientific research,
composing and performing music, painting pictures,
writing fiction, persuading humans and other AGIs to
adopt its opinions, and every other task including,
most importantly, designing and building ever more capable
AGIs. Life 1.0 was hard-wired; Life 2.0 could alter its
software, but not its hardware; Life 3.0 can alter both
its software and hardware. This may set off an
“intelligence
explosion” of recursive
improvement, since each successive generation of AGIs will be
even better at designing more capable successors, and this cycle
of refinement will not be limited to the glacial timescale of
random evolutionary change, but rather an engineering cycle
which will run at electronic speed. Once the AGI train pulls
out of the station, it may develop from the level of human
intelligence to something as far beyond human cognition as
humans are compared to ants in one human sleep cycle. Here is a
summary of Life 1.0, 2.0, and 3.0.
The emergence of Life 3.0 is something about which we, exemplars of Life 2.0, should be concerned. After all, when we build a skyscraper or hydroelectric dam, we don't worry about, or rarely even consider, the multitude of Life 1.0 organisms, from bacteria through ants, which may perish as the result of our actions. Might mature Life 3.0, our descendants just as much as we are descended from Life 1.0, be similarly oblivious to our fate and concerns as it unfolds its incomprehensible plans? As artificial intelligence researcher Eliezer Yudkowsky puts it, “The AI does not hate you, nor does it love you, but you are made out of atoms which it can use for something else.” Or, as Max Tegmark observes here, “[t]he real worry isn't malevolence, but competence”. It's unlikely a super-intelligent AGI would care enough about humans to actively exterminate them, but if its goals don't align with those of humans, it may incidentally wipe them out as it, for example, disassembles the Earth to use its core for other purposes. But isn't this all just science fiction—scary fairy tales by nerds ungrounded in reality? Well, maybe. What is beyond dispute is that for the last century the computing power available at constant cost has doubled about every two years, and this trend shows no evidence of abating in the near future. Well, that's interesting, because depending upon how you estimate the computational capacity of the human brain (a contentious question), most researchers expect digital computers to achieve that capacity within this century, with most estimates falling within the years from 2030 to 2070, assuming the exponential growth in computing power continues (and there is no physical law which appears to prevent it from doing so). My own view of the development of machine intelligence is that of the author in this “intelligence landscape”.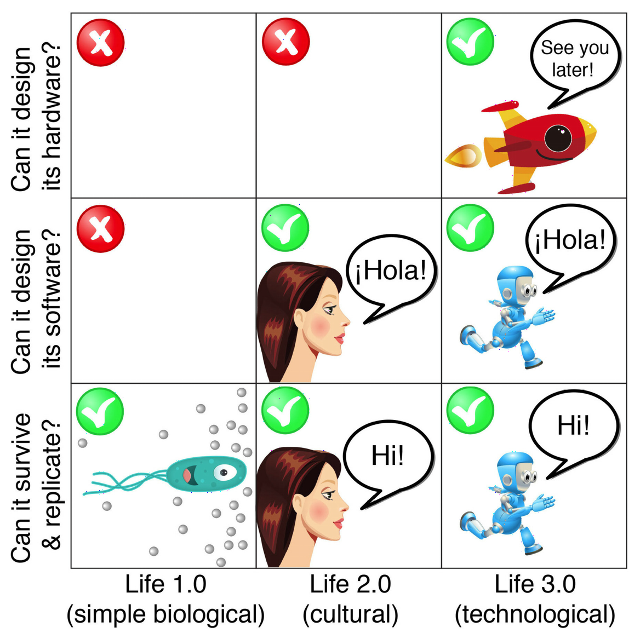
Altitude on the map represents the difficulty of a cognitive task. Some tasks, for example management, may be relatively simple in and of themselves, but founded on prerequisites which are difficult. When I wrote my first computer program half a century ago, this map was almost entirely dry, with the water just beginning to lap into rote memorisation and arithmetic. Now many of the lowlands which people confidently said (often not long ago), “a computer will never…”, are submerged, and the ever-rising waters are reaching the foothills of cognitive tasks which employ many “knowledge workers” who considered themselves safe from the peril of “automation”. On the slope of Mount Science is the base camp of AI Design, which is shown in red since when the water surges into it, it's game over: machines will now be better than humans at improving themselves and designing their more intelligent and capable successors. Will this be game over for humans and, for that matter, biological life on Earth? That depends, and it depends upon decisions we may be making today. Assuming we can create these super-intelligent machines, what will be their goals, and how can we ensure that our machines embody them? Will the machines discard our goals for their own as they become more intelligent and capable? How would bacteria have solved this problem contemplating their distant human descendants? First of all, let's assume we can somehow design our future and constrain the AGIs to implement it. What kind of future will we choose? That's complicated. Here are the alternatives discussed by the author. I've deliberately given just the titles without summaries to stimulate your imagination about their consequences.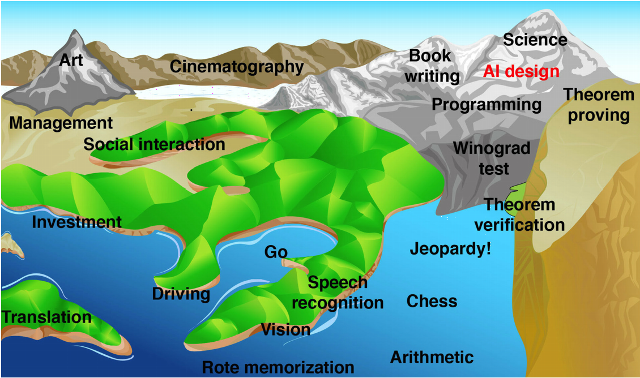
- Libertarian utopia
- Benevolent dictator
- Egalitarian utopia
- Gatekeeper
- Protector god
- Enslaved god
- Conquerors
- Descendants
- Zookeeper
- 1984
- Reversion
- Self-destruction
I'm not sure this chart supports the argument that technology has been the principal cause for the stagnation of income among the bottom 90% of households since around 1970. There wasn't any major technological innovation which affected employment that occurred around that time: widespread use of microprocessors and personal computers did not happen until the 1980s when the flattening of the trend was already well underway. However, two public policy innovations in the United States which occurred in the years immediately before 1970 (1, 2) come to mind. You don't have to be an MIT cosmologist to figure out how they torpedoed the rising trend of prosperity for those aspiring to better themselves which had characterised the U.S. since 1940. Nonetheless, what is coming down the track is something far more disruptive than the transition from an agricultural society to industrial production, and it may happen far more rapidly, allowing less time to adapt. We need to really get this right, because everything depends on it. Observation and our understanding of the chemistry underlying the origin of life is compatible with Earth being the only host to life in our galaxy and, possibly, the visible universe. We have no idea whatsoever how our form of life emerged from non-living matter, and it's entirely possible it may have been an event so improbable we'll never understand it and which occurred only once. If this be the case, then what we do in the next few decades matters even more, because everything depends upon us, and what we choose. Will the universe remain dead, or will life burst forth from this most improbable seed to carry the spark born here to ignite life and intelligence throughout the universe? It could go either way. If we do nothing, life on Earth will surely be extinguished: the death of the Sun is certain, and long before that the Earth will be uninhabitable. We may be wiped out by an asteroid or comet strike, by a dictator with his fat finger on a button, or by accident (as Nathaniel Borenstein said, “The most likely way for the world to be destroyed, most experts agree, is by accident. That's where we come in; we're computer professionals. We cause accidents.”). But if we survive these near-term risks, the future is essentially unbounded. Life will spread outward from this spark on Earth, from star to star, galaxy to galaxy, and eventually bring all the visible universe to life. It will be an explosion which dwarfs both its predecessors, the Cambrian and technological. Those who create it will not be like us, but they will be our descendants, and what they achieve will be our destiny. Perhaps they will remember us, and think kindly of those who imagined such things while confined to one little world. It doesn't matter; like the bacteria and ants, we will have done our part. The author is co-founder of the Future of Life Institute which promotes and funds research into artificial intelligence safeguards. He guided the development of the Asilomar AI Principles, which have been endorsed to date by 1273 artificial intelligence and robotics researchers. In the last few years, discussion of the advent of AGI and the existential risks it may pose and potential ways to mitigate them has moved from a fringe topic into the mainstream of those engaged in developing the technologies moving toward that goal. This book is an excellent introduction to the risks and benefits of this possible future for a general audience, and encourages readers to ask themselves the difficult questions about what future they want and how to get there. In the Kindle edition, everything is properly linked. Citations of documents on the Web are live links which may be clicked to display them. There is no index.
- Vallee, Jacques. The Heart of the Internet. Charlottesville, VA: Hampton Roads Publishing, 2003. ISBN 1-57174-369-3.
- The author (yes, that Jacques Vallee) recounts the history of the Internet from an insider's perspective: first as a member of Doug Engelbart's Augmentation group at SRI from 1971, and later as a developer of the pioneering Planet conferencing system at the Institute for the Future and co-founder of the 1976 spin-off InfoMedia. He does an excellent job both of sketching Engelbart's still unrealised vision of computer networks as a means of connecting human minds in new ways, and in describing how it, like any top-down system design, was doomed to fail in the real world populated by idiosyncratic and innovative human beings. He celebrates the organic, unplanned growth of the Internet so far and urges that it be allowed to continue, free of government and commercial constraints. The present-day state of the Internet worries him as it worries me; he eloquently expresses the risk as follows (p. 162): “As a venture capitalist who invests in high tech, I have to worry that the web will be perceived as an increasingly corrupt police state overlying a maze of dark alleys and unsafe practices outside the rule of law. The public and many corporations will be reluctant to embrace a technology fraught with such problems. The Internet economy will continue to grow, but it will do so at a much slower pace than forecast by industry analysts.” This is precisely the scenario I have come to call “the Internet slum”. The description of the present-day Internet and what individuals can do to protect their privacy and defend their freedom in the future is sketchy and not entirely reliable. For example, on page 178, “And who has time to keep complete backup files anyway?”, which rhetorical question I would answer, “Well, anybody who isn't a complete idiot.” His description of the “Mesh” in chapter 8 is precisely what I've been describing to gales of laughter since 1992 as “Gizmos”—a world in which everything has its own IPv6 address—each button on your VCR, for example—and all connections are networked and may be redefined at will. This is laid out in more detail in the Unicard Ubiquitous section of my 1994 Unicard paper.
- Vallee, Jacques. Forbidden Science. Vol. 2. San Francisco: Documatica Research, 2008. ISBN 978-0-615-24974-2.
- This, the second volume of Jacques Vallee's journals, chronicles the years from 1970 through 1979. (I read the first volume, covering 1957–1969, before I began this list.) Early in the narrative (p. 153), Vallee becomes a U.S. citizen, but although surrendering his French passport, he never gives up his Gallic rationalism and scepticism, both of which serve him well in the increasingly weird Northern California scene in the Seventies. It was in those locust years that the seeds for the personal computing and Internet revolutions matured, and Vallee was at the nexus of this technological ferment, working on databases, Doug Englebart's Augmentation project, and later systems for conferencing and collaborative work across networks. By the end of the decade he, like many in Silicon Valley of the epoch, has become an entrepreneur, running a company based upon the conferencing technology he developed. (One amusing anecdote which indicates how far we've come since the 70s in mindset is when he pitches his conferencing system to General Electric who, at the time, had the largest commercial data network to support their timesharing service. They said they were afraid to implement anything which looked too much like a messaging system for fear of running afoul of the Post Office.) If this were purely a personal narrative of the formative years of the Internet and personal computing, it would be a valuable book—I was there, then, and Vallee gets it absolutely right. A journal is, in many ways, better than a history because you experience the groping for solutions amidst confusion and ignorance which is the stuff of real life, not the narrative of an historian who knows how it all came out. But in addition to being a computer scientist, entrepreneur, and (later) venture capitalist, Vallee is also one of the preeminent researchers into the UFO and related paranormal phenomena (the character Claude Lacombe, played by François Truffaut in Steven Spielberg's 1977 movie Close Encounters of the Third Kind was based upon Vallee). As the 1970s progress, the author becomes increasingly convinced that the UFO phenomenon cannot be explained by extraterrestrials and spaceships, and that it is rooted in the same stratum of the human mind and the universe we inhabit which has given rise to folklore about little people and various occult and esoteric traditions. Later in the decade, he begins to suspect that at least some UFO activity is the work of deliberate manipulators bent on creating an irrational, anti-science worldview in the general populace, a hypothesis expounded in his 1979 book, Messengers of Deception, which remains controversial three decades after its publication. The Bay Area in the Seventies was a kind of cosmic vortex of the weird, and along with Vallee we encounter many of the prominent figures of the time, including Uri Geller (who Vallee immediately dismisses as a charlatan), Doug Engelbart, J. Allen Hynek, Anton LaVey, Russell Targ, Hal Puthoff, Ingo Swann, Ira Einhorn, Tim Leary, Tom Bearden, Jack Sarfatti, Melvin Belli, and many more. Always on a relentlessly rational even keel, he observes with dismay as many of his colleagues disappear into drugs, cults, gullibility, pseudoscience, and fads as that dark decade takes its toll. In May 1979 he feels himself to be at “the end of an age that defied all conventions but failed miserably to set new standards” (p. 463). While this is certainly spot on in the social and cultural context in which he meant it, it is ironic that so many of the standards upon which the subsequent explosion of computer and networking technology are based were created in those years by engineers patiently toiling away in Silicon Valley amidst all the madness. An introduction and retrospective at the end puts the work into perspective from the present day, and 25 pages of end notes expand upon items in the journals which may be obscure at this remove and provide source citations for events and works mentioned. You might wonder what possesses somebody to read more than five hundred pages of journal entries by somebody else which date from thirty to forty years ago. Well, I took the time, and I'm glad I did: it perfectly recreated the sense of the times and of the intellectual and technological challenges of the age. Trust me: if you're too young to remember the Seventies, it's far better to experience those years here than to have actually lived through them.
- Virk, Rizwan. The Simulation Hypothesis. Cambridge, MA: Bayview Books, 2019. ISBN 978-0-9830569-0-4.
-
Before electronic computers had actually been built,
Alan Turing
mathematically proved a fundamental and profound property of
them which has been exploited in innumerable ways as they
developed and became central to many of our technologies and
social interactions. A computer of sufficient complexity, which
is, in fact, not very complex at all, can simulate any
other computer or, in fact, any deterministic physical
process whatsoever, as long as it is understood sufficiently to
model in computer code and the system being modelled does not
exceed the capacity of the computer—or the patience of the
person running the simulation. Indeed, some of the first
applications of computers were in modelling physical processes
such as the flight of ballistic projectiles and the
hydrodynamics of explosions. Today, computer modelling and
simulation have become integral to the design process for
everything from high-performance aircraft to toys, and many
commonplace objects in the modern world could not have been
designed without the aid of computer modelling. It certainly
changed my life.
Almost as soon as there were computers, programmers realised
that their ability to simulate, well…anything
made them formidable engines for playing games. Computer gaming
was originally mostly a furtive and disreputable activity,
perpetrated by gnome-like programmers on the graveyard shift
while the computer was idle, having finished the
“serious” work paid for by unimaginative customers
(who actually rose before the crack of noon!). But as the
microelectronics revolution slashed the size and price of
computers to something individuals could afford for their own
use (or, according to the computer Puritans of the previous
generations, abuse), computer gaming came into its own. Some
modern
computer games have production and promotion budgets larger
than Hollywood movies, and their characters and story lines have
entered the popular culture. As computer power has grown
exponentially, games have progressed from tic-tac-toe, through
text-based adventures, simple icon character video games, to
realistic three dimensional simulated worlds in which the players
explore a huge world, interact with other human players and
non-player characters (endowed with their own rudimentary
artificial intelligence) within the game, and in some games and
simulated worlds, have the ability to extend the simulation by
building their own objects with which others can interact. If
your last experience with computer games was the Colossal Cave
Adventure or Pac-Man, try a modern game or virtual
world—you may be amazed.
Computer simulations on affordable hardware are already
beginning to approach the limits of human visual resolution,
perception of smooth motion, and audio bandwidth and
localisation, and some procedurally-generated game worlds are
larger than a human can explore in a million lifetimes.
Computer power is forecast to continue to grow exponentially for
the foreseeable future and, in the Roaring Twenties, permit
solving a number of problems through “brute
force”—simply throwing computing power and massive
data storage capacity at them without any deeper fundamental
understanding of the problem. Progress in the last decade in
areas such as speech recognition, autonomous vehicles, and
games such as Go are precursors to what will be possible
in the next.
This raises the question of how far it can go—can computer
simulations actually approach the complexity of the real world,
with characters within the simulation experiencing lives as rich
and complex as our own and, perhaps, not even suspect they're
living in a simulation? And then, we must inevitably speculate
whether we are living in a simulation, created by
beings at an outer level (perhaps themselves many levels deep in
a tree of simulations which may not even have a top level).
There are many reasons to suspect that we are living in a
simulation; for many years I have said it's “more likely
than not”, and others, ranging from Stephen Hawking to
Elon Musk and Scott Adams, have shared my suspicion. The
argument is very simple.
First of all, will we eventually build computers sufficiently
powerful to provide an authentic simulated world to conscious
beings living within it? There is no reason to doubt that we
will: no law of physics prevents us from increasing the power of
our computers by at least a factor of a trillion from those of
today, and the lesson of technological progress has been that
technologies usually converge upon their physical limits and
new markets emerge as they do, using their
capabilities and funding further development. Continued growth in
computing power at the rate of the last fifty years should begin
to make such simulations possible some time between 2030 and the
end of this century.
So, when we have the computing power, will we use it to build
these simulations? Of course we will! We have been
building simulations to observe their behaviour and interact
with them, for ludic and other purposes, ever since the first
primitive computers were built. The market for games has only
grown as they have become more complex and realistic. Imagine
what if will be like when anybody can create a whole
society—a whole universe—then let it run to
see what happens, or enter it and experience it first-hand.
History will become an experimental science. What
would have happened if the Roman empire had discovered the
electromagnetic telegraph? Let's see!—and while we're at
it, run a thousand simulations with slightly different initial
conditions and compare them.
Finally, if we can create these simulations which are so
realistic the characters within them perceive them as their real
world, why should we dare such non-Copernican arrogance as to
assume we're at the top level and not ourselves within a
simulation? I believe we shouldn't, and to me the argument that
clinches it is what I call the “branching factor”.
Just as we will eventually, indeed, I'd say, inevitably, create
simulations as rich as our own world, so will the beings within
them create their own. Certainly, once we can, we'll create
many, many simulations: as many or more as there are running copies of
present-day video games, and the beings in those simulations
will as well. But if each simulation creates its own
simulations in a number (the branching factor) even a
tiny bit larger than one, there will be exponentially
more observers in these layers on layers of simulations than at
the top level. And, consequently, as non-privileged observers
according to the
Copernican
Principle, it is not just more likely than not, but
overwhelmingly probable that we are living in a simulation.
The author of this book, founder of
Play Labs @ MIT,
a start-up accelerator which works in conjunction with the
MIT Game Lab,
and producer of a number of video games, has come to the same
conclusion, and presents the case for the simulation hypothesis
from three perspectives: computer science, physics, and the
unexplained (mysticism, esoteric traditions, and those enduring
phenomena and little details which don't make any sense when
viewed from the conventional perspective but may seem perfectly
reasonable once we accept we're characters in somebody else's
simulation).
Computer Science. The development of computer games is
sketched from their origins to today's three-dimensional
photorealistic multiplayer environments into the future, where
virtual reality mediated by goggles, gloves, and crude haptic
interfaces will give way to direct neural interfaces to the
brain. This may seem icky and implausible, but so were pierced
lips, eyebrows, and tongues when I was growing up, and now I see
them everywhere, without the benefit of directly jacking in to a
world larger, more flexible, and more interesting than
the dingy one we inhabit. This is sketched in eleven steps, the
last of which is the Simulation Point, where we achieve the
ability to create simulations which “are virtually
indistinguishable from a base physical reality.” He
describes, “The Great Simulation is a video game that is
so real because it is based upon incredibly sophisticated
models and rendering techniques that are beamed directly into
the mind of the players, and the actions of artificially
generated consciousness are indistinguishable from real
players.” He identifies nine technical hurdles which
must be overcome in order to arrive at the Simulation Point.
Some, such as simulating a sufficiently large world and
number of players, are challenging but straightforward
scaling up of things we're already doing, which will become
possible as computer power increases. Others, such as
rendering completely realistic objects and incorporating
physical sensations, exist in crude form today but will
require major improvements we don't yet know how to
build, while technologies such as interacting directly with
the human brain and mind and endowing non-player characters
within the simulation with consciousness and human-level
intelligence have yet to be invented.
Physics. There are a number of aspects of the physical
universe, most revealed as we have observed at very
small and very large scales, and at speeds and time intervals
far removed from those with which we and our ancestors
evolved, that appear counterintuitive if not bizarre
to our expectations from everyday life. We can express them
precisely in our equations of quantum mechanics, special
and general relativity, electrodynamics, and the
standard models of particle physics and cosmology, and
make predictions which accurately describe our observations,
but when we try to understand what is really going on or
why it works that way, it often seems puzzling and
sometimes downright weird.
But as the author points out, when you view these aspects of
the physical universe through the eyes of a computer game
designer or builder of computer models of complex physical
systems, they look oddly familiar. Here is how I expressed
it thirteen years ago in my 2006 review of Leonard Susskind's
The Cosmic Landscape:
What would we expect to see if we inhabited a simulation? Well, there would probably be a discrete time step and granularity in position fixed by the time and position resolution of the simulation—check, and check: the Planck time and distance appear to behave this way in our universe. There would probably be an absolute speed limit to constrain the extent we could directly explore and impose a locality constraint on propagating updates throughout the simulation—check: speed of light. There would be a limit on the extent of the universe we could observe—check: the Hubble radius is an absolute horizon we cannot penetrate, and the last scattering surface of the cosmic background radiation limits electromagnetic observation to a still smaller radius. There would be a limit on the accuracy of physical measurements due to the finite precision of the computation in the simulation—check: Heisenberg uncertainty principle—and, as in games, randomness would be used as a fudge when precision limits were hit—check: quantum mechanics.
Indeed, these curious physical phenomena begin to look precisely like the kinds of optimisations game and simulation designers employ to cope with the limited computer power at their disposal. The author notes, “Quantum Indeterminacy, a fundamental principle of the material world, sounds remarkably similar to optimizations made in the world of computer graphics and video games, which are rendered on individual machines (computers or mobile phones) but which have conscious players controlling and observing the action.” One of the key tricks in complex video games is “conditional rendering”: you don't generate the images or worry about the physics of objects which the player can't see from their current location. This is remarkably like quantum mechanics, where the act of observation reduces the state vector to a discrete measurement and collapses its complex extent in space and time into a known value. In video games, you only need to evaluate when somebody's looking. Quantum mechanics is largely encapsulated in the tweet by Aatish Bhatia, “Don't look: waves. Look: particles.” It seems our universe works the same way. Curious, isn't it? Similarly, games and simulations exploit discreteness and locality to reduce the amount of computation they must perform. The world is approximated by a grid, and actions in one place can only affect neighbours and propagate at a limited speed. This is precisely what we see in field theories and relativity, where actions are local and no influence can propagate faster than the speed of light. The unexplained. Many esoteric and mystic traditions, especially those of the East such as Hinduism and Buddhism, describe the world as something like a dream, in which we act and our actions affect our permanent identity in subsequent lives. Western traditions, including the Abrahamic religions, see life in this world as a temporary thing, where our acts will be judged by a God who is outside the world. These beliefs come naturally to humans, and while there is little or no evidence for them in conventional science, it is safe to say that far more people believe and have believed these things and have structured their lives accordingly than those who have adopted the strictly rationalistic viewpoint one might deduce from deterministic, reductionist science. And yet, once again, in video games we see the emergence of a model which is entirely compatible with these ancient traditions. Characters live multiple lives, and their actions in the game cause changes in a state (“karma”) which is recorded outside the game and affects what they can do. They complete quests, which affect their karma and capabilities, and upon completing a quest, they may graduate (be reincarnated) into a new life (level), in which they retain their karma from previous lives. Just as players who exist outside the game can affect events and characters within it, various traditions describe actors outside the natural universe (hence “supernatural”) such as gods, angels, demons, and spirits of the departed, interacting with people within the universe and occasionally causing physical manifestations (miracles, apparitions, hauntings, UFOs, etc.). And perhaps the simulation hypothesis can even explain absence of evidence: the sky in a video game may contain a multitude of stars and galaxies, but that doesn't mean each is populated by its own video game universe filled with characters playing the same game. No, it's just scenery, there to be admired but with which you can't interact. Maybe that's why we've never detected signals from an alien civilisation: the stars are just procedurally generated scenery to make our telescopic views more interesting. The author concludes with a summary of the evidence we may be living in a simulation and the objection of sceptics (such that a computer as large and complicated as the universe would be required to simulate a universe). He suggests experiments which might detect the granularity of the simulation and provide concrete evidence the universe is not the continuum most of science has assumed it to be. A final chapter presents speculations as to who might be running the simulation, what their motives might be for doing so, and the nature of beings within the simulation. I'm cautious of delusions of grandeur in making such guesses. I'll bet we're a science fair project, and I'll further bet that within a century we'll be creating a multitude of simulated universes for our own science fair projects. - Wolfram, Stephen. A New Kind of Science. Champaign, IL: Wolfram Media, 2002. ISBN 1-57955-008-8.
- The full text of this book may now be read online.