« July 2006 | Main | September 2006 »
Thursday, August 31, 2006
Reading List: The Ghost Brigades
- Scalzi, John. The Ghost Brigades. New York: Tor, 2006. ISBN 0-7653-1502-5.
- After his stunning fiction debut in Old Man's War, readers hoping for the arrival on the scene of a new writer of Golden Age stature held their breath to see whether the author would be a one book wonder or be able to repeat. You can start breathing again—in this, his second novel, he hits another one out of the ballpark. This story is set in the conflict-ridden Colonial Union universe of Old Man's War, some time after the events of that book. Although in the acknowledgements he refers to this as a sequel, you'd miss little or nothing by reading it first, as everything introduced in the first novel is explained as it appears here. Still, if you have the choice, it's best to read them in order. The Colonial Special Forces, which are a shadowy peripheral presence in Old Man's War, take centre stage here. Special Forces are biologically engineered and enhanced super-soldiers, bred from the DNA of volunteers who enlisted in the regular Colonial Defense Forces but died before they reached the age of 75 to begin their new life as warriors. Unlike regular CDF troops, who retain their memories and personalities after exchanging their aged frame for a youthful and super-human body, Special Forces start out as a tabula rasa with adult bodies and empty brains ready to be programmed by their “BrainPal” appliance, which also gives them telepathic powers. The protagonist, Jared Dirac, is a very special member of the Special Forces, as he was bred from the DNA of a traitor to the Colonial Union, and imprinted with that person's consciousness in an attempt to figure out his motivations and plans. Things didn't go as expected, and Jared ends up with two people in his skull, leading to exploration of the meaning of human identity and how our memories (or those of others) make us who we are, along the lines of Robert Heinlein's I Will Fear No Evil. The latter was not one of Heinlein's better outings, but Scalzi takes the nugget of the idea and runs with it here, spinning a yarn that reads like Heinlein's better work. In the last fifty pages, the Colonial Union universe becomes a lot more ambiguous and interesting, and the ground is laid for a rich future history series set there. This book has less rock-em sock-em combat and more character development and ideas, which is just fine for this non-member of the video game generation. Since almost anything more I said would constitute a spoiler, I'll leave it at that; I loved this book, and if you enjoy the best of Heinlein, you probably will as well. (One quibble, which I'll try to phrase to avoid being a spoiler: for the life of me, I can't figure out how Sagan expects to open the capture pod at the start of chapter 14 (p. 281), when on p. 240 she couldn't open it, and since then nothing has happened to change the situation.) For more background on the book and the author's plans for this universe, check out the Instapundit podcast interview with the author.
Posted at
22:27
![]()
Monday, August 28, 2006
Windows Screen Savers: Sky Version 3.1a Released
Version 3.1a, a bug fix update to the recently updated Sky Screen Saver, was posted today. This corrects an error which has been present in this screen saver for eleven years, ever since its launch on 16-bit Windows in August 1995, but which went undetected until hawk-eyed reader Hendrik Oehme observed that in the interval between midnight Universal Time and local midnight, the date shown in the Universal Time display was that of the local time zone, not that at the Greenwich meridian.Posted at
23:12
![]()
Sunday, August 27, 2006
ETSET Version 3.3 Posted
Version 3.3 of ETSET, which translates electronic texts written in human readable form into LaTeX (and thence to PostScript and PDF, if you wish), HTML (either single document or individual chapters with navigation links), or Palm Markup Language (PML) to produce eReader books which can be read on a variety of handheld platforms, is now available. Version 3.3 is a minor update to version 3.2 which corrects errors in HTML generation when Unicode character entities are enabled which could result in mismatched opening and closing quotes and character entities in the document and chapter titles being inadvertently translated into HTML escape sequences. A new “--match-quotes” option scans for potentially mismatched double quotes, but since it reports multiple paragraph quotations in which all paragraphs other than the last begin with a quote but omit the closing quote as potentially mismatched, you'll have to review these manually if they occur in your document. ETSET is a C++/STL program written using the Literate Programming methodology in the CWEB System; the source code and complete documentation (both user-level and internal) may be read online (PDF file).Posted at
16:04
![]()
Friday, August 25, 2006
Reading List: Fantastic Realities
- Wilczek, Frank. Fantastic Realities. Singapore: World Scientific, 2006. ISBN 981-256-655-4.
- The author won the 2004 Nobel Prize in Physics for his discovery of “asymptotic freedom” in the strong interaction of quarks and gluons, which laid the foundation of the modern theory of Quantum Chromodynamics (QCD) and the Standard Model of particle physics. This book is an anthology of his writing for general and non-specialist scientific audiences over the last fifteen years, including eighteen of his “Reference Frame” columns from Physics Today and his Nobel prize autobiography and lecture. I had eagerly anticipated reading this book. Frank Wilczek and his wife Betsy Devine are co-authors of the 1988 volume Longing for the Harmonies, which I consider to be one of the best works of science popularisation ever written, and whose “theme and variation” structure I adopted for my contemporary paper “The New Technological Corporation”. Wilczek is not only a brilliant theoretician, he has a tremendous talent for explaining the arcana of quantum mechanics and particle physics in lucid prose accessible to the intelligent layman, and his command of the English language transcends pedestrian science writing and sometimes verges on the poetic, occasionally crossing the line: this book contains six original poems! The collection includes five book reviews, in a section titled “Inspired, Irritated, Inspired”, the author's reaction to the craft of reviewing books, which he describes as “like going on a blind date to play Russian roulette” (p. 305). After finishing this 500 page book, I must sadly report that my own experience can be summed up as “Inspired, Irritated, Exasperated”. There is inspiration aplenty and genius on display here, but you're left with the impression that this is a quickie book assembled by throwing together all the popular writing of a Nobel laureate and rushed out the door to exploit his newfound celebrity. This is not something you would expect of World Scientific, but the content of the book argues otherwise. Frank Wilczek writes frequently for a variety of audiences on topics central to his work: the running of the couplings in the Standard Model, low energy supersymmetry and the unification of forces, a possible SO(10) grand unification of fundamental particles, and lattice QCD simulation of the mass spectrum of mesons and hadrons. These are all fascinating topics, and Wilczek does them justice here. The problem is that with all of these various articles collected in one book, he does them justice again, again, and again. Four illustrations: the lattice QCD mass spectrum, the experimentally measured running of the strong interaction coupling, the SO(10) particle unification chart, and the unification of forces with and without supersymmetry, appear and are discussed three separate times (the latter four times) in the text; this gets tedious. There is sufficient wonderful stuff in this book to justify reading it, but don't feel duty-bound to slog through the nth repetition of the same material; a diligent editor could easily cut at least a third of the book, and probably close to half without losing any content. The final 70 pages are excerpts from Betsy Devine's Web log recounting the adventures which began with that early morning call from Sweden. The narrative is marred by the occasional snarky political comment which, while appropriate in a faculty wife's blog, is out of place in an anthology of the work of a Nobel laureate who scrupulously avoids mixing science and politics, but still provides an excellent inside view of just what it's like to win and receive a Nobel prize.
Posted at
23:47
![]()
Saturday, August 19, 2006
Tom Swift and His Air Glider Now Online
The twelfth installment in the Tom Swift saga, Tom Swift and His Air Glider, is now available in the Tom Swift and His Pocket Library collection. As usual, HTML, PDF, PDA eReader, and plain ASCII text editions suitable for reading off- or online are available. In this episode, our plucky young inventor-hero shows that his talent for asking for trouble equals or exceeds that for mechanics, as he and his companions fly into Siberia to rescue an injustly accused man from the Czar's secret police, dodging, along the way, nihilist revolutionaries and even the French, while hoping to make the expedition pay by looting a Siberian platinum mine. (When this book was published in 1912, the Bolshevik revolution was five years in the future.) I have corrected numerous typographic and formatting errors in this edition of the text, but have deferred close proofreading until I get around to reading the book on my PDA. Consequently, corrections from eagle-eyed readers are more than welcome. Note the comments in the main Pocket Library page before reporting archaic spelling (for example, “gasolene”) as an error.Posted at
00:13
![]()
Wednesday, August 16, 2006
Reading List: The Evidence for the Top Quark
- Staley, Kent W. The Evidence for the Top Quark. Cambridge: Cambridge University Press, 2004. ISBN 0-521-82710-8.
- A great deal of nonsense and intellectual nihilism has been committed in the name of “science studies”. Here, however, is an exemplary volume which shows not only how the process of scientific investigation should be studied, but also why. The work is based on the author's dissertation in philosophy, which explored the process leading to the September 1994 publication of the “Evidence for top quark production in pp collisions at √s = 1.8 TeV” paper in Physical Review D. This paper is a quintessential example of Big Science: more than four hundred authors, sixty pages of intricate argumentation from data produced by a detector weighing more than two thousand tons, and automated examination of millions and millions of collisions between protons and antiprotons accelerated to almost the speed of light by the Tevatron, all to search, over a period of months, for an elementary particle which cannot be observed in isolation, and finally reporting “evidence” for its existence (but not “discovery” or “observation”) based on a total of just twelve events “tagged” by three different algorithms, when a total of about 5.7 events would have been expected due to other causes (“background”) purely by chance alone. Through extensive scrutiny of contemporary documents and interviews with participants in the collaboration which performed the experiment, the author provides a superb insight into how science on this scale is done, and the process by which the various kinds of expertise distributed throughout a large collaboration come together to arrive at the consensus they have found something worthy of publication. He explores the controversies about the paper both within the collaboration and subsequent to its publication, and evaluates claims that choices made by the experimenters may have a produced a bias in the results, and/or that choosing experimental “cuts” after having seen data from the detector might constitute “tuning on the signal”: physicist-speak for choosing the criteria for experimental success after having seen the results from the experiment, a violation of the “predesignation” principle usually assumed in statistical tests. In the final two, more philosophical, chapters, the author introduces the concept of “Error-Statistical Evidence”, and evaluates the analysis in the “Evidence” paper in those terms, concluding that despite all the doubt and controversy, the decision making process was, in the end, ultimately objective. (And, of course, subsequent experimentation has shown the information reported in the Evidence paper to be have been essentially correct.) Popular accounts of high energy physics sometimes gloss over the fantastically complicated and messy observations which go into a reported result to such an extent you might think experimenters are just waiting around looking at a screen waiting for a little ball to pop out with a “t” or whatever stencilled on the side. This book reveals the subtlety of the actual data from these experiments, and the intricate chain of reasoning from the multitudinous electronic signals issuing from a particle detector to the claim of having discovered a new particle. This is not, however, remotely a work of popularisation. While attempting to make the physics accessible to philosophers of science and the philosophy comprehensible to physicists, each will find the portions outside their own speciality tough going. A reader without a basic understanding of the standard model of particle physics and the principles of statistical hypothesis testing will probably end up bewildered and may not make it to the end, but those who do will be rewarded with a detailed understanding of high energy particle physics experiments and the operation of large collaborations of researchers which is difficult to obtain anywhere else.
Posted at
18:00
![]()
Monday, August 14, 2006
Web: Truncated Downloads with Internet Explorer
Over the years, I've gotten sporadic reports from people who claim files they've downloaded from the Fourmilab server are “corrupted”. In every such case, the file on the server turned out to be just fine, racking up hundreds of downloads a day by others who reported no problems with it. Most of these reports are from users attempting to download large Zipped archives on Windows platforms which, after being downloaded, their Unzip program reported as malformed. Frequently, users who report this claim to have tried downloading the file on multiple occasions, encountering the problem every time. Back in the dawn of time, problems like this were usually the result of somebody on a Windows machine retrieving a binary file such as a Zipped archive or self-extracting executable without setting “binary” mode in their FTP client, which would then helpfully expand every Unix line feed character into a DOS carriage return / line feed sequence, utterly wrecking binary data. But HTTP downloads of files with MIME types as common as “application/zip” shouldn't be vulnerable to such problems, so the whole thing remained a mystery. I recently decided to see if I could get to the bottom of this. While such reports are rare (I'd say about one every other month), there's no way to estimate the actual incidence of the problem, whatever it may be, since many people may just give up and never report it. So, whenever anybody reports such a problem, I now try to identify their download attempt(s) in the HTTP server log, and send them a reply requesting a variety of information about their system and the circumstances of the error, including asking them to attach the actual “corrupted” file(s) they received. Few people reply to these messages, and often the response is sufficiently incoherent and incomplete that it's of no diagnostic use. Today, however, I got a reply which is perfect in every regard, and now I'm more mystified than ever! The user is running on Windows 2000 with Microsoft Internet Explorer 6, both at current service pack and patch levels. No error message was reported by Internet Explorer for the download of the files, yet WinZip reported the files as invalid archives. The files the user sent me, as it turned out, were both truncated copies of the actual downloads present on my server. In each of the two files, the portion received by the user was identical to the initial part of the file on the server, but the file received was incomplete: in one case 3027188 instead of 7114310 bytes, and in the other just 192228 of 1423984 bytes on the server. Now here's where it gets weird (cue X-Files music). The entries from the Apache HTTP server log show these downloads as having completed normally, with the full file length transferred:
200.x.x.18 - - [06/Aug/2006:14:21:49 +0200]
"GET /homeplanet/download/3.1/hp3full.zip HTTP/1.1"
200 7114310
"-"
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)"
200.x.x.18 - - [09/Aug/2006:16:19:41 +0200]
"GET /homeplanet/download/3.1/hp3lite.zip HTTP/1.1"
200 1423984
"http://www.fourmilab.ch/homeplanet/"
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)"
(I have manually wrapped these long lines onto multiple lines to avoid truncation and obscured the second and third bytes of the user's IP address in the interest of privacy.) In fact, the log showed three attempts to download the 7.1 Mb hp3full.zip file, all apparently complete and successful as seen from the server side, yet the file received by the user was incomplete.
So, the question becomes “Is there some circumstance in which Microsoft Internet Explorer appears to download an entire file from a Web server, but only writes some portion of it to the user's disc?” If this is the case, it isn't obvious there's much the operators of Web sites can do to mitigate the frustration this causes their visitors, other than making them aware of the problem and instructing them how to use the command line FTP client which comes with 32-bit Windows to download problem files. (Every file at this site is accessible with either HTTP or FTP; this is increasingly rare in these days of name virtual hosting and paranoia about even anonymous-only FTP access, so this solution, such as it is, may not work for many other sites.)
Posted at
21:13
![]()
Thursday, August 10, 2006
Home Planet Version 3.3RC1 Now Available
The first release candidate of version 3.3 of Home Planet (this link goes to the page describing the current 3.1/3.2 release) is now available for downloading and testing by “bleeding edge” early adopters from the following links, all Zipped archives containing long file names and multiple directories, which must be extracted with the requisite options using a utility which understands these refinements.- Download Home Planet “Lite” Edition (1.5 Mb)
- Download Home Planet “Full” Edition (14 Mb)
- Download Home Planet Upgrade (Lite => Full) (13 Mb)
- Download Home Planet Source Code (14 Mb)
Posted at
22:54
![]()
Tuesday, August 8, 2006
Mathematics: Zipf's Law and the AOL Query Database
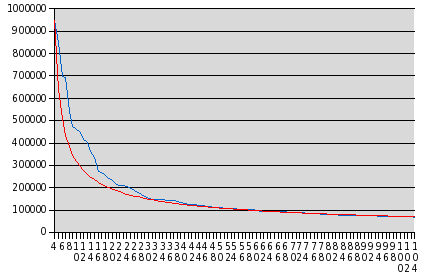
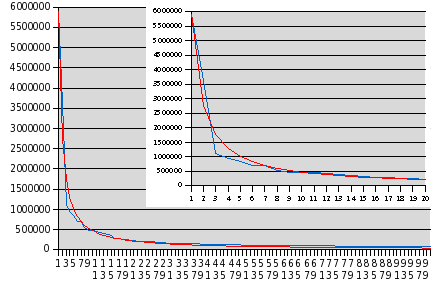
You may have heard about the most recent scandal at AOL, which compiled a statistical sampling of more than twenty million search terms entered by more than 650,000 of their trusting customers, and then made this database available to the public for research purposes. While user names were replaced by numbers, these numbers provide a “thread” by which queries by a given user may be identified so that if, for example, a user entered some piece of information which permits their identity to be discerned, all the other queries they made during the sampling period may be identified as theirs. AOL have admitted that this wasn't, even by AOL standards, such a bright thing to do, and have pulled the database from their “research.aol.com” site (the very domain name almost tempts one to chuckle), but one of the great problems or strengths of the Internet, depending upon whether you're the one who has made a tremendous goof or everybody else looking to exploit it, is that it's essentially impossible to “un-publish” something once it gets loose in digital form. While AOL have deleted the file, it has already been mirrored all over the world: here is a handy list of places in case you're interested in getting a copy for your own research. (Note: even as a Gzipped TAR file containing individually Gzipped text files, this is a 440 megabyte download; if you don't have a high-speed Internet connection, or you pay by the amount you download, this probably isn't for you.) Well, I do have a 2 Mbit/sec leased line which is almost idle in the inbound direction, so I set my development machine downloading this file overnight, and by the crack of noon it had arrived chez moi. The first thing I wanted to look at was, as you might guess, the most popular search terms. I wrote a little Perl program which parsed the query strings from the records, divided them into words, and computed a word frequency histogram. Here are the most common twenty words in queries from the database, with the number of occurrences in the complete list of 36,389,567 records:| 1 | com | 5,907,621 |
| 2 | www | 3,618,471 |
| 3 | of | 1,127,393 |
| 4 | in | 946,216 |
| 5 | the | 848,407 |
| 6 | for | 699,547 |
| 7 | and | 693,682 |
| 8 | 543,052 | |
| 9 | to | 473,015 |
| 10 | free | 460,569 |
| 11 | s | 448,308 |
| 12 | yahoo | 416,583 |
| 13 | a | 403,375 |
| 14 | myspace | 364,657 |
| 15 | org | 336,277 |
| 16 | new | 273,897 |
| 17 | http | 269,856 |
| 18 | on | 256,646 |
| 19 | pictures | 240,376 |
| 20 | county | 234,618 |
Posted at
21:38
![]()
Monday, August 7, 2006
Fourmilab: New In-house Server in Production
 The new Fourmilab in-house file and compute server went into production last week-end. With the exception of tape backups (which will be transferred when a tape changer for the new server arrives), all of the functions of the Sun in-house server installed in 1998 have now been assumed by the new machine, a Dell PowerEdge 2800 with two Intel Xeon 2.8 GHz dual-core CPUs, which (since each of the cores is itself “hyper threaded”) gives the equivalent of eight symmetric processors sharing 12 Gb of common memory. There are eight 300 Gb 10,000 RPM SCSI drives on two channels, all hot-swappable from the front panel, configured as a 7 drive RAID-5 array with a total capacity of 1.8 Terabytes with one hot spare which, when mounted, looks like this in a “df -h”:
The new Fourmilab in-house file and compute server went into production last week-end. With the exception of tape backups (which will be transferred when a tape changer for the new server arrives), all of the functions of the Sun in-house server installed in 1998 have now been assumed by the new machine, a Dell PowerEdge 2800 with two Intel Xeon 2.8 GHz dual-core CPUs, which (since each of the cores is itself “hyper threaded”) gives the equivalent of eight symmetric processors sharing 12 Gb of common memory. There are eight 300 Gb 10,000 RPM SCSI drives on two channels, all hot-swappable from the front panel, configured as a 7 drive RAID-5 array with a total capacity of 1.8 Terabytes with one hot spare which, when mounted, looks like this in a “df -h”:
Filesystem Size Used Avail Use% Mounted on /dev/sda3 9.5G 404M 8.6G 5% / /dev/sda10 1.4T 124G 1.2T 10% /home /dev/sda5 190G 7.8G 172G 5% /server /dev/sda7 9.5G 151M 8.9G 2% /tmp /dev/sda6 24G 3.9G 19G 18% /usr /dev/sda8 9.5G 309M 8.7G 4% /varYep, that's right—1.4 Terabytes on /home! There is a /server partition which is configured identically to that of machines in the server farm. This permits the in-house server to be the definitive copy of the public server content, serve as a testbed, and act as the hub from which updates are published onto the server farm with rdist. The new server runs Fedora Core 5 Linux, which installed on the first attempt with no problems whatsoever. Although this machine, on the private local network, is protected by the firewall, I decided to install SELinux in “Enforcing mode” to gain experience with that package with the intent of eventually deploying it on the public servers. The presence of a /server partition configured identically to the server farm machines allows this machine, in extremis, to join the public server farm with only the change of its IP address and plugging its network cables into the DMZ hubs. The machine is remarkably quiet. Even with the eight disc drives and twin dual-core processors, it makes a lot less racket than one of the PowerEdge 1800 “blade” servers in the server farm. This may be because the limited height of the rack servers means their fans need to spin much faster to pull the air through, but still the 2800 makes far less noise than the Sun server, which has the same number of disc drives and a small fraction of the memory and CPU capacity. The fully qualified name of this server on the private local network is “ceres.lan.fourmilab.ch”. I'm naming in-house servers after asteroids now—tens of thousands have been named, so I'll run out of Class C IP space long before I run out of names! At the time the new firewall was installed, I partitioned the Domain Name Service for the site into a public view which resolves only hosts in the externally accessible host.fourmilab.ch IP address block (193.8.230.0/24), and an internal view which also includes hosts on the LAN (host.lan.fourmilab.ch, 10.1.0.0/16) and servers on the DMZ (host.dmz.fourmilab.ch, 10.2.0.0/16). The Fourmilab Network Architecture chart (to which I haven't yet added ceres) describes how these networks are interconnected.
Although the machine is shown here with a Fourmilab “Bitmobile” crash cart attached, it is usually administered as a “headless” system via ssh and the Dell Remote Access Controller, which provides remote console access across the Web.
Posted at
23:33
![]()
Sunday, August 6, 2006
Reading List: Rats
- Sullivan, Robert. Rats. New York: Bloomsbury, [2004] 2005. ISBN 1-58234-477-9.
- Here we have one of the rarest phenomena in publishing: a thoroughly delightful best-seller about a totally disgusting topic: rats. (Before legions of rat fanciers write to berate me for bad-mouthing their pets, let me state at the outset that this book is about wild rats, not pet and laboratory rats which have been bred for docility for a century and a half. The new afterword to this paperback edition relates the story of a Brooklyn couple who caught a juvenile Bedford-Stuyvesant street rat to fill the empty cage of their recently deceased pet and, as it it matured, came to regard it with such fear that they were afraid even to release it in a park lest it turn and attack them when the cage was opened—the author suggested they might consider the strategy of “open the cage and run like hell” [p. 225–226]. One of the pioneers in the use of rats in medical research in the early years of the 20th century tried to use wild rats and concluded “they proved too savage to maintain in the laboratory” [p. 231].) In these pages are more than enough gritty rat facts to get yourself ejected from any polite company should you introduce them into a conversation. Many misconceptions about rats are debunked, including the oft-cited estimate that the rat and human population is about the same, which would lead to an estimate of about eight million rats in New York City—in fact, the most authoritative estimate (p. 20) puts the number at about 250,000 which is still a lot of rats, especially once you begin to appreciate what a single rat can do. (But rat exaggeration gets folks' attention: here is a politician claiming there are fifty-six million rats in New York!) “Rat stories are war stories” (p. 34), and this book teems with them, including The Rat that Came Up the Toilet, which is not an urban legend but a well-documented urban nightmare. (I'd be willing to bet that the incidence of people keeping the toilet lid closed with a brick on the top is significantly greater among readers of this book.) It's common for naturalists who study an animal to develop sympathy for it and defend it against popular aversion: snakes and spiders, for example, have many apologists. But not rats: the author sums up by stating that he finds them “disgusting”, and he isn't alone. The great naturalist and wildlife artist John James Audubon, one of the rare painters ever to depict rats, amused himself during the last years of his life in New York City by prowling the waterfront hunting rats, having received permission from the mayor “to shoot Rats in the Battery” (p. 4). If you want to really get to know an animal species, you have to immerse yourself in its natural habitat, and for the Brooklyn-based author, this involved no more than a subway ride to Edens Alley in downtown Manhattan, just a few blocks from the site of the World Trade Center, which was destroyed during the year he spent observing rats there. Along with rat stories and observations, he sketches the history of New York City from a ratty perspective, with tales of the arrival of the brown rat (possibly on ships carrying Hessian mercenaries to fight for the British during the War of American Independence), the rise and fall of rat fighting as popular entertainment in the city, the great garbage strike of 1968 which transformed the city into something close to heaven if you happened to be a rat, and the 1964 Harlem rent strike in which rats were presented to politicians by the strikers to acquaint them with the living conditions in their tenements. People involved with rats tend to be outliers on the scale of human oddness, and the reader meets a variety of memorable characters, present-day and historical: rat fight impresarios, celebrity exterminators, Queen Victoria's rat-catcher, and many more. Among numerous fascinating items in this rat fact packed narrative is just how recent the arrival of the mis-named brown rat, Rattus norvegicus, is. (The species was named in England in 1769, having been believed to have stowed away on ships carrying lumber from Norway. In fact, it appears to have arrived in Britain before it reached Norway.) There were no brown rats in Europe at all until the 18th century (the rats which caused the Black Death were Rattus rattus, the black rat, which followed Crusaders returning from the Holy Land). First arriving in America around the time of the Revolution, the brown rat took until 1926 to spread to every state in the United States, displacing the black rat except for some remaining in the South and West. The Canadian province of Alberta remains essentially rat-free to this day, thanks to a vigorous and vigilant rat control programme. The number of rats in an area depends almost entirely upon the food supply available to them. A single breeding pair of rats, with an unlimited food supply and no predation or other causes of mortality, can produce on the order of fifteen thousand descendants in a single year. That makes it pretty clear that a rat population will grow until all available food is being consumed by rats (and that natural selection will favour the most aggressive individuals in a food-constrained environment). Poison or trapping can knock down the rat population in the case of a severe infestation, but without limiting the availability of food, will produce only a temporary reduction in their numbers (while driving evolution to select for rats which are immune to the poison and/or more wary of the bait stations and traps). Given this fact, which is completely noncontroversial among pest control professionals, it is startling that in New York City, which frets over and regulates public health threats like second-hand tobacco smoke while its denizens suffer more than 150 rat bites a year, many to children, smoke-free restaurants dump their offal into rat-infested alleys in thin plastic garbage bags, which are instantly penetrated by rats. How much could it cost to mandate, or even provide, rat-proof steel containers for organic waste, compared to the budget for rodent control and the damages and health hazards of a large rat population? Rats will always be around—in 1936, the president of the professional society for exterminators persuaded the organisation to change the name of the occupation from “exterminator” to “pest control operator”, not because the word “exterminator” was distasteful, but because he felt it over-promised what could actually be achieved for the client (p. 98). But why not take some simple, obvious steps to constrain the rat population? The book contains more than twenty pages of notes in narrative form, which contain a great deal of additional information you don't want to miss, including the origin of giant inflatable rats for labour rallies, and even a poem by exterminator guru Bobby Corrigan. There is no index.
Posted at
21:33
![]()
Saturday, August 5, 2006
The Hacker's Diet: Excel 2003 Macro Update
I have posted an update to The Hacker's Diet computer tools Excel macros which work around a long-standing bug in Excel. All the way from Excel 2.1 through 5 (in my opinion, when this once-great program stopped improving and began to spiral into the abyss exemplified by Clippy, VBA macro viruses, and other abominations) you could “link” a macro sheet to a document and define a macro which was automatically run when the document was loaded which opened other related documents such as auxiliary worksheets and charts. As long as all the related documents were kept in the same directory, all you had to do was double click on the main document and the entire ensemble of interrelated documents would be opened automatically. With the advent of Excel 5, the wheels fell off this happy situation. Now, the main document would find the macro sheet all right, but when the initialisation macro tried to open the other documents, the user would get a “File not found” error message. If the main document were opened from the “File/Open” menu everything would work, but double clicking the document from Explorer or even opening it from the “Recent documents” menu in Excel would fall flat on its face. Apparently (and this is pure inference and speculation on my part, unconfirmed by experiment), in Excel versions before 5, the process of opening a document set the current directory for the drive on which it resided to the document's parent directory, but in version 5 and later, the current directory was unchanged. Consequently, when a linked macro attempted to open a document without an explicit directory specification, the open would fail unless the user had previously navigated to that directory explicitly, for example with the “File/Open” menu. There is, however, a function in the classic Excel macro language called GET.DOCUMENT which, if called with an argument of 2, returns the full directory path of the current document. You can use this to open auxiliary documents in the same directory with code like the following, which appears on line 263 of The Hacker's Diet macros for Excel 2003:
=OPEN(GET.DOCUMENT(2) & "\" & "WEIGHIST.XLS",0,FALSE)
This prefixes the directory of the yearly weight log to the name of the cumulative weight history file and guarantees that it will be opened from the same directory.
If you've been irritated by not being able to double click a yearly log document and have the history open correctly, download the Excel 2003 macros and the problem should go away. If you're maintaining Excel macros which suffer from this problem, this is how to fix it.
Posted at
00:50
![]()
Friday, August 4, 2006
Puzzle: Civilians in Space
The first part of today's puzzle should be easy for space buffs, but may surprise those whose space information comes from the often uninformed prattle of the legacy media. The question is:Who was the first civilian to fly in space?To avoid argumentative nitpicking, let's agree that “civilian” means a person who was not a member of an armed service at the time of their flight—a prior military career does not count. NASA astronauts who were military officers were “on assignment” to NASA, but remained military personnel unless they explicitly resigned their commissions and became NASA civilian employees. Further, let us take “fly in space” according to the definition of spaceflight by the Fédération Aéronautique Internationale (FAI): a flight to an altitude of more than 100 kilometres.
Posted at
20:47
![]()
Wednesday, August 2, 2006
Windows Screen Savers: Terranova, Millennium, and Home Planet Updated
Concluding the twenty oh-six simmering summer super screen saver swoop, the Terranova, Millennium, and Home Planet screen savers have been updated to be compatible with dual screen configurations and store their settings individually for each user in the Windows registry (which also permits users without administrator privilege to save their settings). Retrocausality notwithstanding, there isn't much point in counting down to a date in the past, so the Millennium screen saver now, by default, shows the days remaining until Black Tuesday, January 19th, 2038, when 32-bit signed Unix time() values go negative. The Home Planet screen saver now uses the NASA Visible Earth imagery introduced in the Home Planet 3.2 Update package instead of the topographic map used previously; the new image has higher spatial resolution (still modest, as befits a screen saver) as well as natural colour rendering of a cloudless Earth. Update: After further reflection I made a few additional tweaks to the Home Planet screen saver. This is the only Fourmilab screen saver which generates images whose ratio of width to height (aspect ratio) of two to one exceeds that of most computer displays. (The Slide Show screen saver shows images of any shape, but it does not generate images.) The other screen savers size their images based on the smaller of the screen's dimensions (usually the height, but portrait format displays work as well), but to better adapt to screen size, the Home Planet screen saver takes both the width and height of the display into account when computing the size of the image. On a dual screen configuration, this resulted in images which were so large they almost always spanned the two screens and, in addition, showed magnification artefacts due to being scaled up from the 768×384 pixel Earth image database. First of all, I've replaced the Earth image with a 2048×1024 pixel database; this avoids scaling problems on almost all displays of the present and near future. While a two megabyte screen saver would have been scandalous when Home Planet was first released in 1995, today it's par for the course. Secondly, I added code which detects dual screen configurations and other “ultra-wide” displays (defined as a screen which is more than twice as wide as it is high), and sets the image scale based on a screen of half that width; this causes the map display to be the same size on a machine with two monitors of the same resolution as on a system with a single such monitor. Finally, the image is now positioned so as to never span the two monitors (assuming they are arranged horizontally and share the same resolution). (2006-08-03 19:37 UTC).Posted at
23:34
![]()
Tuesday, August 1, 2006
Switzerland Turns 715; Fourmilab Still Standing
According to tradition, the Swiss Confederation traces its origin to a pact made on August 1st, 1291 among the original three cantons. Although historical records confirming this event are ambiguous, since 1899 Switzerland has celebrated August 1st as its national day and ever since the 700th anniversary of the Confederation in 1991 (the first year I was present for the event), it has actually been a holiday—previously it was a regular work day. This year, like the last, Google Switzerland had a commemorative logo.

This evening our village had the traditional celebration with music from the brass band, a speech by a political figure (this year, one of the canton's members in Switzerland's “Senate”), and the traditional bonfire and fireworks. The bonfire was rather more exciting than usual, as shortly after it was lit a stiff wind came up (fortunately, directed away from most of the crowd), which caused the fire to extend in a blowtorch-like manner almost horizontally. From nearby, there was a roar and crackling reminiscent of the sound of the Space Shuttle's solid rocket boosters, and despite the chilly weather and wind, everybody started moving back simply due to the heat, although doubtless also with self-preservation in mind, as the wind direction was fickle.

Since the weather through most of July has been unusually hot and dry, there was substantial concern about the possibility of fires started by bonfires and fireworks. (In Switzerland, just about every kind of fireworks, including the really heavy artillery, is legal and readily available, and teenaged boys often show up at these village celebrations with an armamentarium that rivals that of the official display.) Fortunately, it drizzled for most of the day until mid-afternoon, when the sky cleared to fluffy clouds scudding along in a brisk wind. I've lived in this village for fourteen years now, and not once has either the first of August celebration nor the Désalpe at the end of September been rained out; don't tell me wishing for good weather doesn't work!
Even though there was an impressive plume of flame and showers of sparks departing into the darkling sky, only some blades of grass on the football field got singed and everything is still standing, at least until next year.
Posted at
23:49
![]()